
14.1 Архитектура компьютеров: процессоры и шины
==990
Несмотря на стремительную трансформацию компьютеров, существуют некоторые основополагающие идеи, свойственные всей цифровой электронике. Знакомиться с ними проще всего, разбирая классическую архитектуру с общим каналом обмена данными, показанную на блок-схеме 14.2 .
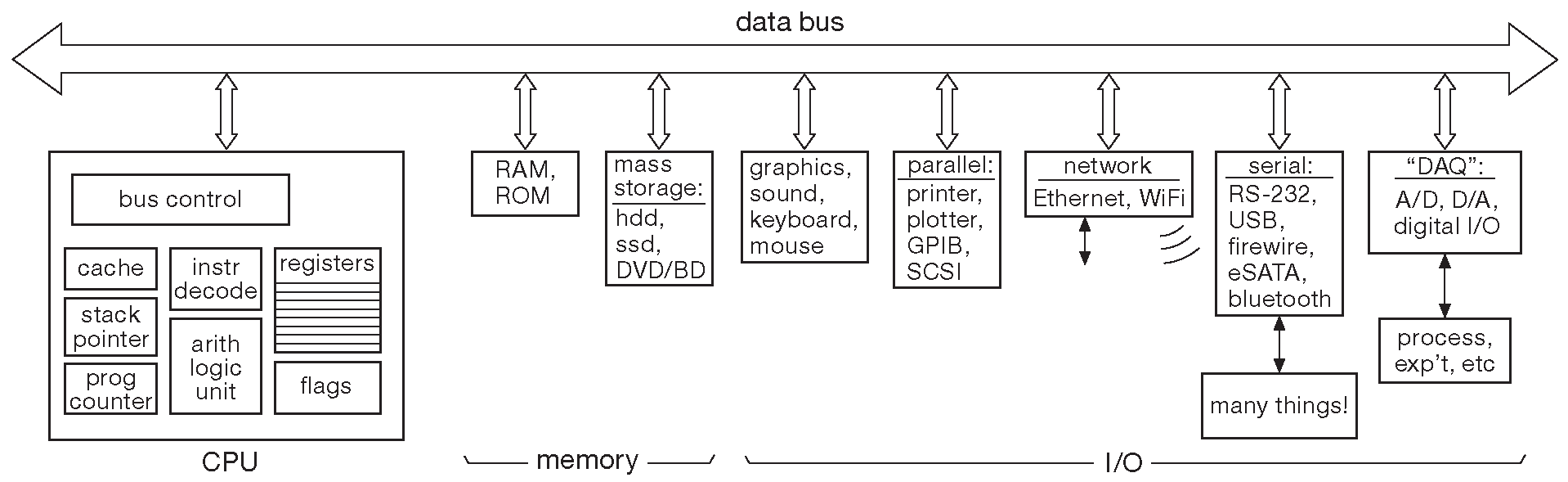
Рис. 14.2 Классическая вычислительна машина с шинной архитектурой
Основная идея состоит в объединении различных устройств общим набором линий – «шиной» вместо мешанины прямых связей «точка-точка» ( rat’s nest ). Такая схема использует гораздо меньше проводов, а из-за того, что традиционно большая часть задач решаются с помощью ЦПУ, использовать раздельные пути передачи данных нет необходимости _4 . Если процессор желает сохранить данные по некоторому адресу в памяти, он должен выставить желаемый адрес и данные на соответствующие линии шины, после чего активизировать сигнал записи. Блок памяти получает адрес и принимает данные. Если же наоборот, данные требуются процессору, он выставляет только адрес и активирует сигнал чтения. Память принимает адрес и выдаёт на шину данные. Так же выглядит обмен с любым другим устройством на шине, каждому из которых отведён некоторый диапазон адресов.
Чтобы понять, как конкретно происходит обмен, надо рассмотреть остальные компоненты со схемы 14.2 .
14.1.1 CPU
Центральное процессорное устройство ( CPU ) - сердце вычислительной машины. Компьютеры работают с данными, нарезанными на слова . Размер машинного слова может лежать в диапазоне от 4 до 64 разрядов и более. В современных компьютерах чаще всего встречаются цифры 32 и 64 разряда. Байт имеет ширину 8 разрядов, полубайт ( 4 разряда ) иногда называют «ниблом» . Та часть ЦПУ, которая называется декодирующей логикой ( instruction decoder ), разбирает поступающие на вход данные, чтобы понять, что требуется делать на очередном шаге программы. Арифметическо-логическое устройство ( ALU ) выполняет арифметические и логические действия над данными в регистрах ( и, иногда, в памяти ). Счётчик команд ( program counter ) [* или «счётчик программы» ] хранит адрес исполняемой инструкции в программе. В обычном состоянии он увеличивается по завершении текущей команды, но может быть обновлён полностью при выполнении инструкции перехода или вызова подпрограммы. Блок управления шиной ( bus control circuitry ) отвечает за обмен данными с памятью и устройствами ввода-вывода. БОльшая часть вычислительных устройств имеет также указатель стека ( stack pointer ), разговор о котором впереди. Флаги переноса ( C ), нуля ( Z ) и знака ( S ) используются в инструкциях с условиями. У всех производительных процессоров есть также кэш-память, хранящая команды и данные, к которым происходили последние обращения.
Современные производительные процессоры способны выполнять «параллельные» вычисления, при которых несколько сидящих на одной шине процессоров проводят вычисления одновременно. Часто такая архитектура реализуется в виде «многоядерных» кристаллов. Чтобы упростить тему не будем обсуждать разработку компьютера, а ограничим список вопросов подключением к однопроцессорной машине [* в данном контексте правильнее говорить «однокристальной», ибо не имеет значения сколько ядер внутри: главное - внешняя шина одна ] , исполняющей инструкции последовательно в формате «прочитать-выполнить-записать».
==991
14.1.2 Память
Все вычислительные устройства имеют тот или иной вариант оперативной памяти или памяти «со случайным доступом» ( RAM ) _5 . В больших машинах объём ОЗУ исчисляется гигабайтами, а микроконтроллеры имеют от сотен байт до единиц мегабайт ( типичные цифры [* давно устаревшие, как это обычно бывает с конкретными цифрам ] 4K...64K _6 ). Цикл чтения/записи оперативной памяти занимает менее 100 ns . Динамическая оперативная память высокой плотности _7 требует наличия питающего напряжения , т.е. при его отключении информация исчезает ( можно было бы назвать такую память «забывчивой» ). В каждом компьютере есть также какой-то объём постоянной памяти ( обычно в виде памяти «только для чтения» - flash ROM ), которая требуется для начальной загрузки и амнезией не страдает, сохраняя записанную информацию даже в отсутствие питания. В случае микроконтроллеров такая память хранит и всю программу. Память разбирается подробнее в §14.4 .
Чтобы получить данные, ЦПУ должно указать их «адрес». Большинство вычислительных устройств адресует память побайтно, начиная с нулевого адреса и последовательно до последнего байта в адресном пространстве. [* Не следует путать «адресацию», как степень фрагментирования носителя, с форматом обращения к носителю при чтении или записи. Скажем, в 32-разрядном процессоре ARM A9 обращение всегда идёт кратно машинному слову, т.е. по 4 байта, хотя выполнять действия над отдельными байтами процессор может и использует побайтовую адресацию, а сами микросхемы памяти чаще всего имеют «естественную» разрядность 1 байт ] . Так как большинство вычислительных устройств имеют машинные слова величиной 2 байта и более, чтение и запись выполняются по несколько байт за раз с соответствующим увеличением ширины шины данных.
И программа, и данные во время работы хранятся в памяти. ЦПУ считывает из неё инструкцию, выясняет, что надо делать, и выполняет соответствующую операцию. Чаще всего при этом требуются какие-то данные. Вычислительные машины общего назначения сохраняют программу и данные в одном блоке памяти ( т.н. «фон-Неймановская» архитектура ) и без дополнительных данных не способны отличить одно от другого ( случается, программа «слетает» и начинает «выполнять» данные ). Процессоры для встраиваемых применений часто делают по «Гарвардской» архитектуре, в которой данные и программ располагаются в разных блоках памяти, причём программа чаще всего в постоянной памяти.
Большую часть времени компьютеры циклически выполняют некоторую ограниченную группу инструкций. Это значит, что можно увеличить производительность, сохраняя копии ячеек памяти, к которым происходит обращение, в небольшой, но очень быстрой кэш-памяти ( cache ). Процессор, имеющий такую память, всегда сначала проверяет кэш, прежде чем обратиться к «медленной» основной памяти. Если группа исполняемых инструкций невелика, то число «кэш попаданий» [* т.е. обнаружения нужных данный в кэше ] может достигать 95% обращений, радикально увеличивая скорость исполнения.
14.1.3 Накопители большой ёмкости
==992
Обычные вычислительные машины активно используют накопители большой ёмкости жёсткие диски ( HDD - магнитная память), твердотельные накопители ( SSD - полупроводниковая память ) и оптические диски ( CD, DVD, Blu-ray ), причём последние бывают двух видов: перезаписываемые и «только для чтения», а жёсткие и твердотельные накопители всегда перезаписываемые. Последовательные издания данной книги неизменно демонстрировали одну тенденцию: восторги по поводу «выдающихся» параметров «новейшей» электроники выглядят очень наивно уже через несколько лет _8 . Поэтому просто поставим здесь зарубку: мы живём в эпоху терабайтных дисков, 16-гигабайтных микросхем постоянной и 1-гигабайтных ИМС оперативной памяти ( в \(10\space^3...10\space^4\) раза больше, чем в момент выхода предыдущей редакции ).
14.1.4 Графика, сеть, параллельные и последовательные порты
В большинстве компьютеров имеются стандартные средства коммуникации с пользователем, сетью и внешней периферией. Предполагается, что читатель уже знаком с этими понятиями. СтОит только отметить, что имеется явно видимая тенденция отказа от параллельных интерфейсов ( внутренних IDE и SCSI, а равно и внешнего CENTRONICS ) и перехода на последовательные ( SATA, USB, FireWire, Ethernet ). Последовательные интерфейсы обеспечивают сравнимую или более высокую пропускную способность и одновременно упрощение подключения вкупе со снижением электрического шума. Разговор о параллельных и последовательных коммуникационных портах продолжится в начале §14.5 .
14.1.5 Ввод-вывод в реальном времени
В экспериментах, при управлении процессами и протоколировании событий или в столь экзотических задачах, как синтез речи требуются A/D и D/A устройства, которые могут общаться с компьютером в «реальном времени», т.е. когда все упомянутые события и происходят. Возможности открываются безграничные, и набор типичных АЦП, несколько быстрых ЦАПов и некоторое количество цифровых «портов» ( последовательных или параллельных ) для передачи данных позволяют творить интересные вещи _9 . Перечисленные периферийные устройства выпускаются для всех типов популярных компьютерных шин, как внутренних ( PCI, PCIe ), так и внешних ( USB, FireWire, Ethernet), в частности масса вариантов есть среди приборов фирмы National Instruments. Постоянно увеличивается использование внешних портов, дающих простоту подключения, пониженных уровень цифрового шума и универсальность: можно использовать ноутбуки и смартфоны, а в них доступа к внутренним шинам нет. Если требуется что-то особенное - больше скорости, измерительных каналов или какие-то специальные функции ( генератор тока, синтезатор частоты, формирователь задержек и т.п. ), можно собрать его самостоятельно. Именно здесь сведения о работе шины и навык программирования, полезные сами по себе, становятся совершенно незаменимыми.
14.1.6 Шина данных
Общение между центральным процессором и памятью или периферией происходит на шине - наборе общих линий, по которым движутся данные. Использование общей шины существенным образом упрощает взаимодействие: в её отсутствие потребовались бы многопроводные соединения в каждой паре общающихся друг с другом абонентов 10 . Минимальная аккуратность при проектировании позволяет получить рабочих результат.
Шину постепенно развиваются и достигли уже такого быстродействия и уровня сложности, что использование их в приборе требует заметной квалификации разработчика. Это основная причина для изучения старой простой шины PC104/ISA, которая позволяет обойтись без осложнений при построении системы. Шина ISA впервые появилась в IBM PC, а сейчас живёт в формате PC104, хорошо себя чувствует и поддерживается более чем 75 производителями оборудования. Будучи спрошен о предполагаемом сроке её жизни, коллега авторов заявил, что «она всех нас закопает» 11 .
В общем случае шина данных имеет кратный машинному слову набор линий DATA: 8 разрядов для небольших процессоров и контроллеров и от 16 до 64 разрядов в более сложных микрокомпьютерах. Некоторое количество линий ADDRESS указывает абонента, с которым идёт общение, а группа сигналов CONTROL задают характер действия ( обмен данными с ЦПУ, обработка прерываний, прямой доступ к памяти и т.д. ). Все линии данных, а также некоторые управляющие линии - двунаправленные . Уровни на них задаются буферами с Z-состоянием или вентилями с открытым коллектором [* рис. 10.29 ] и подтягивающим резистором, который ставят в самом дальнем конце линии, чтобы он поработал ещё и терминатором, см. §12.10.1 и Приложение _H . Подтягивающие резисторы ставят и в случае Z-буферов, если линия длинная.
==993
Буфера с третьим состоянием и открытым коллектором позволяют неактивным устройствам отключаться от шины, потому что в каждый момент времени выдавать в канал данные может только одно устройство. В каждом вычислительном устройстве имеется хорошо документированный протокол, однозначно определяющий процедуру выдачи данных на шину. Несоблюдение такого протокола приводит к полному хаосу, когда все абоненты предают свои данные одновременно.
Рассмотрение 8-разрядного варианта PC104 на примерах будет продолжено после знакомства с ЦПУ и системой команд.
==993
4 Общие разделяемые параллельные шины активно использовались во времена миникомпьютеров ( шина “Unibus” фирмы DEC ) и микрокомпьютеров ( в формате «стандартной промышленной архитектуры» ( ISA ), которая и сейчас работает в виде шины PC104 для стандарта embedded-PC ). Но с тех пор шины развились в гораздо более сложные конструкции. Современные персональные компьютеры содержат множество самых разных шин, объединяемых «мостами» с названиями типа «южный», «северный» и т.п. Задача мостов - разделить скоростной обмен данными ( работу с оперативной памятью ) и взаимодействие с медленными периферийными устройствами. Но, как станет ясно из дальнейшего, элегантность и целесообразность разделяемых каналов связи проигрывает по производительности схеме «точка-точка» ( rat’s nest ), которая используется в скоростных линиях передачи. <-
5 Название «память со случайным доступом» отражает тот факт, что устройство допускает получение данных по любому адресу и обеспечивает при этом равное время обращения. В этом отличие от устройств с последовательным доступом, например FIFO [* или стека ] . <-
6 Применительно к памяти множитель «K» означает коэффициент \(1024=2^{10}\) . Таким образом, 16KB обозначает 16384 байта. Множителю 1000 в книге соответствует строчная «k». [* К сожалению, устоявшихся подходов к этому вопросу ни в литературе вообще, ни в данной книге в частности нет ] . <-
7 Динамическое ОЗУ - вид памяти, в которой данные хранятся в виде заряда на конденсаторе. Качество конденсатора оставляет желать лучшего, и заряд быстро утекает, требуя постоянного проведения восстановительной процедуры - регенерации. В противоположность динамической, статическая память хранит каждый байт в триггере и регенерации не требует. Зато динамическая память расходует один транзистор на бит данных ( формула «1T» ), а статическая - целых шесть ( формула «6T» ). И статическая, и динамическая память «забывает» все записанные данные при отключении питания, чем отличаются от постоянной памяти: flash и EEPROM. [* Из-за технологических допусков при изготовлении после подачи питания каждый триггер статической памяти устанавливается в некоторое случайное, но стабильное для данной конкретной микросхемы, состояние. Это позволяет создавать уникальный «отпечаток» конкретного устройства. В динамической памяти уникальна скорость утекания заряда, и отпечаток получают, отключая регенерацию на разные промежутки времени ] . <-
8 В первой редакции ( 1980 ) можно обнаружить восторги по поводу жёстких дисков на несколько мегабайт, 2-килобайтной постоянной и 8-килобайтной оперативной памяти. Десятилетие спустя эйфорию вызывали диски по несколько сотен мегабайт, 128-килобайтная постоянная и 512-килобайтная оперативная память. <-
9 И не забывайте о простых «звуковых картах» ( которые сейчас чаще всего интегрированы на материнскую плату ). Их можно использовать в неответственных случаях при «звуковых» частотах выборки, когда точность по постоянному уровню не нужна. На данный момент они позволяют делать многоканальные измерения с точностью 16 разрядов и частотой выборки 192 kHz [* и прочитайте предупреждение в самом низу стр. 900 ( §13.4 ) ] . <-
10 Та же идея воплощена внутри самого кристалла ЦПУ. Там шина данных соединяет АЛУ и регистры. В случае микроконтроллера, имеющего АЦП, порты и прочие элементы на одном кристалле с центральным процессором, а внутренняя шина соединяет воедино все эти узлы. <-
11 Вероятно, он хотел сказать, что PC104 переживёт авторов, а не убьёт , но железной уверенности нет. <-
