
14.2 Система команд процессора
==993
14.2.1 Язык ассемблера и машинные коды
Чтобы понять смысл сигналов на шине и протокол связи, надо понимать, что процессор делает в ходе исполнения различных команд. Здесь самое время разобрать набор команд семейства процессоров Intel x86, обычно используемых с шиной PC104. К сожалению, набор команд большинства реальных процессоров полон заковыристых и узкоспециализированных инструкций, включая артефакты, оставшиеся в наследство от предшествующих моделей, и Intel x86 - не исключение. Поэтому, исходя из задачи разбора сигналов на шине и протокола обмена ( а вовсе не обучения программированию ), рассматриваться будет узкое подмножество общего набора команд x86. Исключив «избыточные» инструкции можно собрать компактную выжимку, которая будет одновременно и понятна, и достаточна для иллюстративных целей. Учебный набор будет использоваться в примерах программирования интерфейсов. Примеры позволяют лучше понять принципы программирования на уровне «машинного» языка, который сильно отличается от языков уровня Си или C++.
Для начала пара слов о «машинном языке» и «языке ассемблера». Процессор воспринимает определённые сочетания нулей и единиц как инструкции и выполняет запрошенные действия. Эти наборы битов образуют «машинный язык». Каждый уникальный двоичный код может занимать один и более байт. Например, команда увеличения регистра ЦПУ на единицу ( инкремент ) имеет длину 1 байт, а загрузка в регистр данных из памяти может занимать от 2 до 8 байт, где первый байт сообщает операцию и приёмник ( регистр ), а остальные уточняют источник ( адрес памяти ). Печальным фактом является вавилонское столпотворение среди машинных языков для разных линеек процессоров и полное отсутствие какой-либо стандартизации в этой области.
[* Стандартизация de-facto ранее происходила путём создания «фан групп» разработчиков, приверженных какой-то конкретной архитектуре за счёт несовместимости системы команд, т.е. программного обеспечения, а также внешних периферийных шин и способов управления. Но высокоуровневые языки программирования размывают и маскируют индивидуальные особенности разных процессоров для больших машин. Хоть какие-то отличия сохраняются пока в сегменте микроконтроллеров ( из-за близости к «железу» ) и на границе GPU ↔ CPU ( из-за слишком заметных отличий в архитектуре )]
Программирование в машинных кодах - исключительно занудное занятие, потому что требует вручную составлять наборы многоразрядных двоичных чисел, где каждый бит должен точно соответствовать спецификации. Вместо этого можно сопоставить с каждой машинной командой текстовый фрагмент на языке ассемблера , где инструкции заменяются мнемониками, а конкретные шестнадцатиричные адреса памяти и переменные - назначенными пользователем символическими именами. Текст на языке ассемблера предаётся в собственно программу-ассемблер, которая преобразует исходных текст в объектный код на машинном языке, а уже он может исполняться целевым процессором. Одна линия текста соответствует одной машинной инструкции, которая может состоять из нескольких байт ( от 1 до 15 для x86 ). Исполнять программу на языке ассемблера ( текст ) непосредственно процессор не может. Чтобы немного освоиться с этими сведениями, разберёмся с подмножеством набора команд и несколькими примерами.
14.2.2 Упрощённый набор команд x86
Семейство процессоров x86 ( Intel, AMD, VIA ) имеет богатый набор команд со специфическими для каждого производителя ответвлениями. Его сложность обязана своим появлением, в том числе, наследию исходного 8-разрядного прародителя i8080. В более поздние модели добавляли дополнительные инструкции, но они по-прежнему могут исполнять машинный код i8086. Для учебного набора пришлось слегка подправить бензопилой буйную поросль команд, оставив 10 арифметических и 11 прочих мнемоник ( табл. 14.1 ).
14.2.2.A Краткий обзор
Несколько пояснений. Шесть первых арифметических инструкций оперируют парой чисел ( «2-операндный» формат ), которые обозначаются символами в формате «b, a» и могут быть любыми из 5 указанных в примечании вариантов. «m» обозначает элемент в памяти, «r» - один из регистров процессора ( в оригинальном i8086 их восемь ). «imm» - сокращение для «immidiate» - непосредственного значения, которое может занимать от 1 до 4 байт, располагающихся в памяти сразу после кода операции. Таким образом, в инструкциях
MOV count, CX ADD small, 02H AND AX, 007FH
аргументы имеют следующий формат: (m,r), (m,imm) и (r,imm). Первая копирует содержимое регистра CX в область памяти с именем «count», вторая прибавляет 2 к области памяти с именем «small», а третья обнуляет девять старших битов 16-разрядного регистра AX , оставляя семь младших в прежнем состоянии ( операция наложения маски или «маскирования» ). Обратите внимание на соглашение о порядке аргументов фирмы Intel: первым указывается адрес назначения, который модифицируется с участием второго аргумента. [* Стоит добавить, что есть и противоположное соглашение, введённое фирмой Motorola - приёмник стоит самым последним аргументом ] .
==994
Четырём последним арифметическим инструкциям требуется только один аргумент, который может быть или адресом в памяти, или регистром. Два примера:
INC count NEG AL
В первом к содержимому памяти «count» прибавляется единица, а во втором изменяется знак величины в регистре AL .
14.2.2.B Небольшое пояснение: адресация аргументов
Перед началом работы надо разобраться с адресацией регистров и памяти. Оригинальный i8086 заявлялся как имеющий восемь регистров «общего назначения», но после чтения документации становится ясно, что бОльшая их часть имеет вполне конкретную функцию ( рис. 14.3 ). Четыре ( A - D ) можно использовать как единые 16-разрядные регистры, например, AX ( где «X» обозначало eXtended - расширенный ), или как пару 8-разрядных регистров, здесь AH, AL ( «верхняя» и «нижняя» половины ) 12 . BX и BP могут работать адресными, то же можно сказать про SI и DI , которые в основном для адресации и используются. Специальные инструкции организации циклов ( выпиленные из короткого списка ) используют регистр C , а инструкции умножения/ деления и ввода-вывода работают с парой A, D .
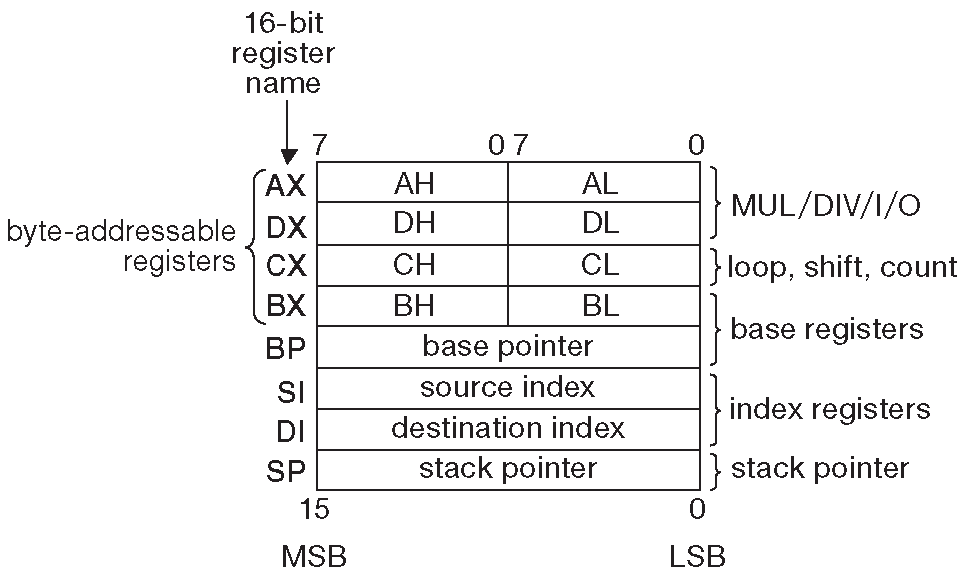
Рис. 14.3 Регистры общего назначения процессора i8086
Табл. 14.1 Урезанная система команд x86 Instruction What you call it What it does arithmetic MOV b,a move a ^ b; a unchanged ADD b,a add a + b ^ b; a unchanged SUB b,a subtract b - a ^ b; a unchanged AND b,a and a AND b ^ b bitwise; a unchanged OR b,a or a OR b ^ b bitwise; a unchanged CMP b,a compare set flags as if b - a; a,b unchanged INC rm increment rm + 1 ^ rm DEC rm decrement rm - 1 ^ rm NOT rm not 1 's complement of rm ^ rm NEG rm negate negative (2's comp) of rm ^ rm stack PUSH rm push push rm onto stack (2 bytes) POP rm pop pop 2 bytes from stack to rm control JMP label jump jump to instr label Jcc label jump conditional jump to instr label if cc true CALL label call push next adr, jump to instr label RET return pop stack, jump to that adr IRET return from int pop stack, restore flags, return STI set interrupt enable interrupts CLI clear interrupt disable interrupts inputloutput IN AX, port input port ^ AX (or AL) OUT port, AX output AX (or AL) ^ port Notes: b,a: any of m,r r,m r,r m,imm r,imm rm: register or memory, via various addressing modes cc: any of Z NZ G GE LE L C NC S NS label: via various addressing modes port: byte (via imm) or word (via DX)
==995
Данные, указанные в инструкции, могут быть непосредственной константой, содержимым регистра или значением в памяти. Такой аргумент специфицируется по значению или по имени, а регистр только по имени, как в примере выше. Для обращения к памяти x86 использует 6 режимов адресации, три из которых разрисованы на диаграмме 14.4 . В языке ассемблера надо прямо указать имя переменной, и тогда её адрес будет подставлен в виде пары байт сразу после кода команды. Но можно положить адрес переменной в адресный регистр ( BX, BP, SI, DI ), а затем использовать инструкцию косвенной адресации через регистр. Два указанных способа можно комбинировать, добавляя непосредственное смещение к значению в адресном регистре, чтобы получить адрес конкретной переменной в памяти. Косвенная адресация выполняется быстрее ( предполагается, что адрес уже лежит в нужном регистре ) и гораздо эффективнее, если требуется работать с набором элементов ( например, строкой или массивом ). Примеры:
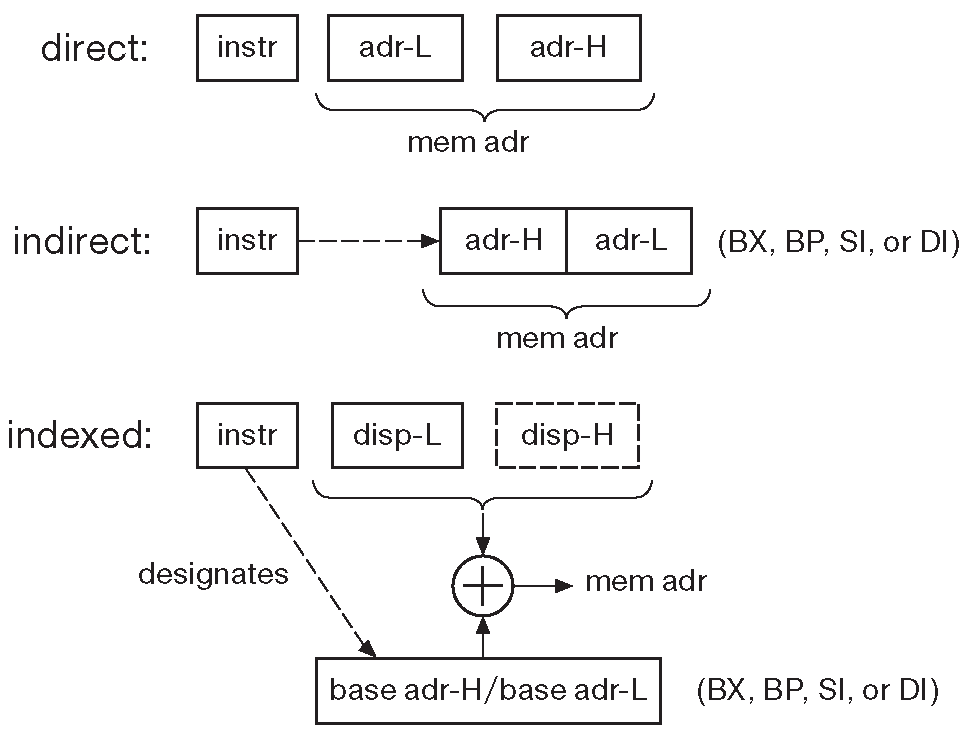
Рис. 14.4 Некоторые режимы адресации
MOV count, 100H ; (direct,immediate) MOV [BX], 100H ; (indirect,immediate) MOV [BX+1000H], AX ; (indexed,register)
Два последних примера предполагают, что в BX уже есть адрес. Последняя инструкция копирует содержимое AX в память по адресу на 4K ( 1000h ) выше того, на который указывает BX .
С адресацией памяти в x86 есть ещё одна сложность, оставшаяся за скобками. Любой из описанных режимов адресации не является физическим адресом в памяти, т.к. адресный регистр BX имеет размер 16 бит ( и может адресовать только 64K байт ). Это на самом деле смещение , и, чтобы получить физический адрес, надо добавить это смещение к 20-разрядной базе , которая получается сдвигом влево на 4 разряда такого же 16-разрядного сегментного регистра ( всего их 4 штуки ). [* Такая адресация называется «страничная ( 64K ) по базе ( BX ) со смещением ( 1000h )». Сегментный же регистр, который здесь только подразумевается, можно представить себе как окно, через которое видны 16 старших битов адреса сегмента, а младшие находятся за правой границей окна. Сегментный регистр выполняет функцию «второй базы», указывающей на область памяти ( «сегмент» ) пользователя в общем адресуемом пространстве процессора ] . Другими словами, x86 позволяет адресовать непрерывный участок памяти длиной 64K байт, расположенной где-то в адресном пространстве величиной 1M байт [ и выровненный на границу 16 байт, т.к. при сдвиге сегментного регистра младшие биты обнуляются ( так сдвиг работает ) ] . Использование 16-разрядной адресации в i8086 изначально было серьёзной архитектурной ошибкой, которая была унаследована от прежних моделей. Новые процессоры, начиная с i80386, такой проблемы уже не имеют и везде работают с полным 32- или 64-разрядным адресом 13 . Чем усложнять учебные примеры, проще забыть о сегментной составляющей, но в реальной жизни в данном вопросе придётся разобраться.
14.2.2.C Продолжение обзора системы команд
Теперь об инструкциях для работы со стеком «PUSH» и «POP». Стек - средство хранения информации, организованное специальным образом. Когда элемент кладётся в стек ( «PUSH» ), он помещается на самый его верх, а когда элемент извлекается ( «POP» ), то убирается самый верхний элемент, т.е. последний положенный в стек. Получается, что стек - линейный список, работа с которым идёт по принципу «последний вошёл - первый вышел» ( LIFO ). Его удобно представлять в виде устройства для раздачи подносов в кафетерии.
Рис. 14.5 показывает, как работает стек. Обычно его организуют как область в обычной оперативной памяти и отводят регистр указателя стека ( SP ), который указывает на вершину стека ( TOS ). В i8086 стек хранит 16-разрядные элементы и растёт вниз по адресам памяти [* от больших адресов к меньшим при заполнении ] . SP автоматически уменьшается на 2 перед каждой операцией «PUSH» [* предекремент ] и увеличивается на 2 после каждой операции «POP» [* постинкремент ] . В показанном примере содержимое 16-разрядного регистра AX кладётся в стек ( «PUSH AX» ), после чего изменившийся SP начинает указывать на последний положенный в стек байт. «POP» возвращает состояние SP и стека в исходное состояние. Стек играет основную роль в вызове подпрограмм и обработке прерываний.
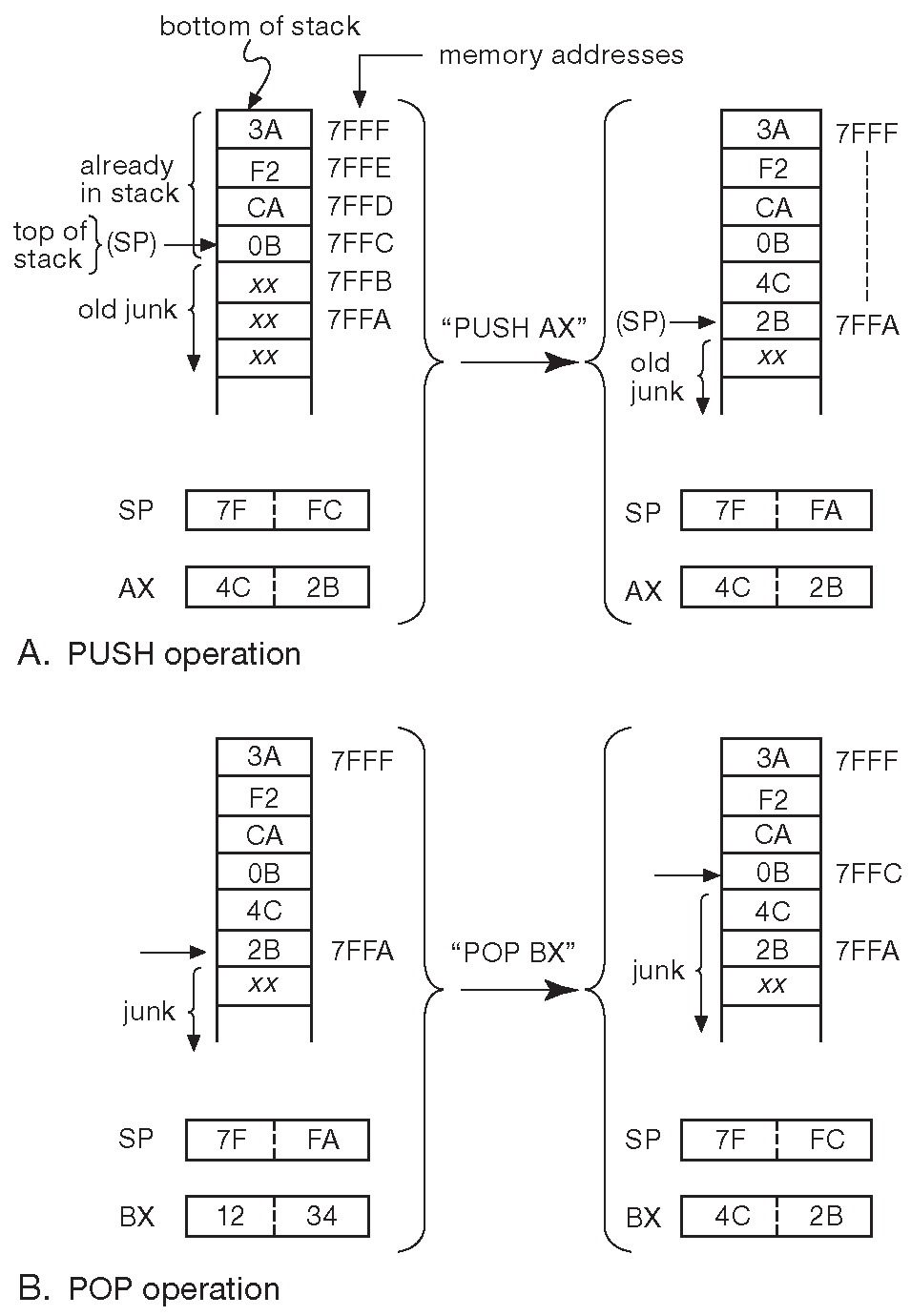
Рис. 14.5 Операции над стеком. (A) Результат работы команды «PUSH» ( в примере используется регистр AX ). (B) Результат работы команды «POP» ( используется регистр BX )
==996
Переход ( «JMP» ) заставляет процессор прервать обычное последовательное исполнение команд и уйти в сторону на указанную в аргументе ( адрес ) инструкцию. При условном переходе ( десять условий, объединённых мнемоникой «Jcc» ) процессор проверяет регистр флагов ( он является частью самого процессора и хранит признаки результатов последней арифметической операции ) и, если состояние флагов соответствует заданному условию, переходит по адресу из аргумента команды. В противном случае ( состояние флагов не соответствует условию ) исполняется следующая за «Jcc» инструкция. Пример использования показан в программе 14.1 . В ней 100 слов [* 16-разрядных ] из массива, начинающегося с адреса 1000h , копируются в новый массив на 1K ( 400h ) байт выше.
Program 14.1
MOV BX, 1000H ;put array address in BX
MOV CL, 100 ;initialize loop counter
LOOP:
MOV AX, [BX] ;copy array element to AX
MOV [BX+400H], AX ;then to new array
ADD BX,2 ;increment array pointer
DEC CL ;decrement counter
JNZ LOOP ;loop if count not zero
NEXT:
(next statement) ;exit here when done
Отметим, что указатель ( адресный регистр BX ) и счётчик циклов ( регистр CL ) загружаются непосредственно. Движение данных идёт через регистр ( здесь взят AX ), потому что i8086 не допускает прямых пересылок память-память ( см. примечания к системе команд ). В конце сотого прохода по циклу CL обнуляется, и условие команды «JNZ» ( переход, если не ноль ) не выполняется. Пример рабочий, но на практике удобнее пользоваться командой пересылки строки , которая выполняется быстрее. Кроме того, должной программной практикой является использование символических имён для размеров и местоположения массива вместо безликих констант наподобие 400h и 1000h .
Инструкция «CALL» отвечает за вызов подпрограммы ( она же «процедура» или «функция» ). Похожа на команду «JMP», но перед передачей управления на новый адрес сохраняет в стеке адрес возврата - положение следующей после «CALL» команды, куда процессор перешёл бы, если бы «CALL» его не прервала. В конце подпрограммы исполняется инструкция «RET», которая забирает из стека адрес возврата и возобновляет исполнение с инструкции после команды «CALL» ( рис. 14.6 ). Три мнемоники «CLI», «STI», «IRET» относятся к работе с прерываниями, о которых будет разговор далее. Наконец, «IN» и «OUT» отвечают за операции ввода-вывода между регистром AX ( AL ) и 16- или 8-разрядным портом ввода-вывода.
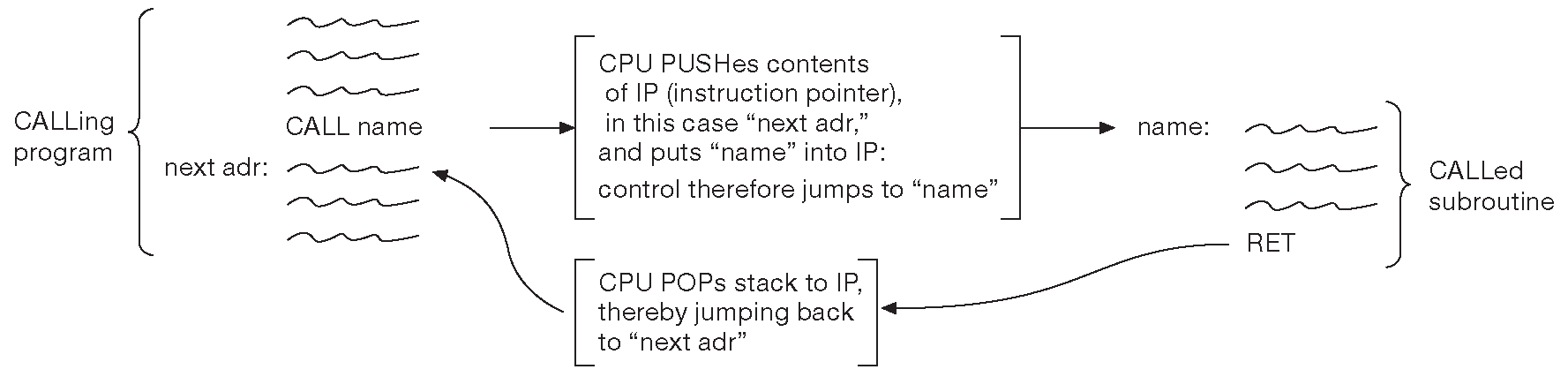
Рис. 14.6 Работа команды «CALL»
14.2.3 Программный пример
Пример с пересылкой массива показывает, что язык ассемблера довольно многословен и описывает много мелких шагов, из которых, как оказывается, состоят казавшиеся простыми действия. Вот ещё один пример. Предположим, требуется увеличивать число n всякий раз, когда оно совпадает с числом m . Это какой-то шаг в большой программе, который на языках высокого уровня записывается одним выражением:
if (n==m) n++; (C, C++, Java) if n==m: (Python) n+=1 IF (N.EQ.M) N=N+1 (FORTRAN) if n=m then n:=n+1; (Pascal)
На языке ассемблера x86 то же действие будет выглядеть как в листинге 14.2 . Программа ассемблера переведёт мнемоники в машинный код: одна строка исходного текста - одна инструкция в объектном коде , причём последний может иметь длину несколько байт. Объектный код размещается в последовательных ячейках программной памяти, откуда, собственно, и считывается в ходе исполнения. [* Т.е. объектный код - это машинный код, записанный в точности так, как он будет выглядеть в программной памяти машины - в виде одной непрерывной последовательности двоичных чисел без какого-либо дополнительного форматирования или символов-разделителей ] . Программу ассемблера надо проинформировать о необходимости отвести память под переменные. Это делается директивой ассемблера или псевдооперацией «DW» ( define word ) [*] . Название «псевдооперация» означает, что исполняемого кода данная директива не создаёт. [* Но во внутренней таблице идентификаторов ассемблера появляется новая запись с пометкой «память» и указанием занимаемого объёма ] . Уникальные символьные имена-метки используются, чтобы отметить конкретное место в программе или данных, например NEXT . Метка удобна для указания адреса назначения при переходе ( JNZ NEXT ). Осмысленные имена меток и комментарии ( отделяются точкой с запятой ) делают код понятнее в первую очередь для самого программиста и дают шанс вспомнить, что здесь писалось, несколько недель спустя. [* Следует заметить, что коментарии в данном фрагменте - пример того, как их писать не надо. Они не сообщают ничего сверх того, что уже говорит код, и только отвлекают внимание ] .
Program 14.2
n DW 0 ;n (a "word") lives here, and
m DW 0 ;m lives here, both initialized to 0
MOV AX, n ;get n
CMP AX, m ;compare
JNZ NEXT ;unequal, do nothing
INC m ;equal, increment m
NEXT:
(next statement)
...
[*]
[Это дружеский привет из седой древности, когда процессоры были большими. Дело в том, что «DW» заставляет отвести память под машинное слово, но отводит два байта памяти, в то время как в современных процессорах машинное слово имеет величину 4 или 8 байт. Это атавизм из мира 16-разрядных машин. Возможно, правильнее будет резервировать память для 64-разрядного процессора директивой «DB 8» - «отвести восемь байт», нежели «DW 4» - «отвести четыре слова» ].
==997
Программирование на ассемблере - не самое интересное занятие, но иногда на нём удобно писать небольшие подпрограммы для обслуживания коротких циклов или необычных режимов ввода-вывода. Ассемблерные программы часто работают быстрее, чем скомпилированные из высокоуровневых языков, поэтому они иногда используются в чувствительных к скорости исполнения местах ( например, вложенных циклах при долгих вычислениях ). Программирование с использованием языков Си и C++ минимизирует ситуации, которые могут потребовать ассемблерного кода. Тем не менее, понять компьютерные интерфейсы, не понимая того, как происходит ввод-вывод на уровне языка ассемблера, невозможно. Соответствие машинных кодов и ассемблерных мнемоник в контексте программирования микроконтроллеров продолжается в наставлении для студентов 14 .
==997
12 В последних моделях их увеличили до 32 разрядов с расширением до 64 бит. <-
13 И с дополнительным уровнем абстракции на пути к физической памяти, т.к. виртуальная память реализуется через таблицы страниц. Но мы, ведь, не об этом? <-
14 Hayes and Horowitz, «Learning the Art of Electronics - a Hands-On Course», Cambridge University Press, 2015. <-
