
6.5 Прерывания и многозадачность
==146
Есть три фактора, влияющих на производительности при обработке прерываний. Первый - время, которое проходит между моментом приёма запроса на прерывание и началом его обработки процессором. Эту задержку называют латентностью прерывания.
Вторым фактором является время, затрачиваемое на подготовку к обработке. Это всё то время, которое процессор тратит на сохранение состояния прерываемой задачи и передачу управления обработчику прерывания. Обычно объём сохраняемых данных о состоянии минимален, в предположении, что обработчик может снизить издержки, сохраняя только те регистры, которые он будет использовать [* время, затрачиваемое здесь, влияет на все без исключения виды прерываний и исключений и должно тратиться только на действительно общие и выполняемые всегда действия ] . Иногда термином «латентность прерывания» называют сумму первых двух факторов.
Третьим фактором производительности обработки прерываний является то, что можно назвать издержками при программном сохранении состояния. Это время, затрачиваемое на действия, не выполняемые автоматически блоком аппаратной обработки прерывания, - сохранение регистров процессора, освобождаемых для программного обработчика. Расходы на сохранение состояния могут меняться в широких пределах, в зависимости от сложности программы обработки. В предельных случаях в многозадачной среде сохранение состояния может вызывать полное переключение контекста задач.
Конечно, на общую производительность влияют и затраты на восстановление состояния и возвращение в прерванную программу. Обсуждаться здесь подробнее они не будут, так как обычно в точности равны времени сохранения состояния ( всё, что было сохранено, должно быть восстановлено ) и не столь сильно влияют на очень значимое время реакции на прерывание.
6.5.1 Латентность реакции на прерывание
В CISC машинах бывают инструкции, требующие на исполнение массу времени и снижающие скорость реакции на прерывание. Стековые же и RISC машины могут иметь очень низкую латентность, потому что инструкции в большинстве стековых машин исполняются за один такт, и в самом худшем случае перед подтверждением прерывания и началом обработки проходит всего несколько тактов.
==147
Но как только начинается обработка прерывания, становится заметна разница между стековыми и RISC компьютерами. После получения запроса RISC процессоры должны пройти сложную процедуру сохранения конвейера, а при возврате из прерывания - процедуру его восстановления, чтобы избежать потерь данных о частично выполненных инструкциях. Стековые машины конвейера не имеют и требуют сохранения только адреса следующей команды. Это значит, что стековые машины могут рассматривать прерывания как формируемый аппаратно вызов подпрограммы. Естественно, из-за того, что вызов процедуры происходит очень быстро, время реакции на прерывание получается совсем небольшим.
6.5.1.1 Возможность повторного запуска инструкций
В стековых машинах возможна только одна связанная с латентностью прерываний проблема. Это проблема потоковых инструкций и циклов в микрокоде.
Потоковые инструкции используются для многократного исполнения какой-либо операции, например, записи верхнего элемента стека в память. Строятся они с использованием имеющихся ресурсов: возможностей повторения ( NC4016 и RTX 2000 ), буфера инструкций ( M17 ) и микрокодовых циклов ( CPU/16 и RTX 32P ). Такие примитивы очень удобны, так как позволяют эффективно форматировать строки или обрабатывать переполнения стека. Проблема в том, что в большинстве случаев потоковые инструкции являются непрерываемыми.
Одним из решений может быть добавление прерываемости с помощью дополнительной аппаратуры, которая может усложнить само вычислительное ядро совсем немного. В обычных процессорах этот вариант создаёт трудноразрешимые сложности с сохранением промежуточных результатов. В стековых машинах подобной проблемы нет, так как промежуточные результаты уже находятся в стеке, который является идеальным средством их сохранения.
Другим подходом является использование программных ограничений, накладываемых на максимальное число повторений в потоковых инструкциях. Таким образом, если надо переместить блок размером 100 слов, то делать это можно, перемещая группы по восемь слов за раз. Латентность прерываний остаётся при этом в разумных пределах при некотором снижении производительности. Как и всегда, существует выбор между абсолютной эффективностью ( при длинных потоковых инструкциях ) и высокой скоростью реакции на прерывание.
В основном те же проблемы выбора и в машинах, использующих микрокод. Тем не менее, существует очень простая стратегия, обеспечивающая наилучшие результаты во всех случаях, которая была реализована в коммерческой версии RTX 32P . Она заключается в обеспечении доступа из микрокода к биту, сообщающему о наличии отложенного запроса на прерывание. Бит проверяется в каждом микроцикле без дополнительных затрат времени. Если запросов на прерывание нет, то можно проводить очередную итерацию. В противном случае адрес потоковой инструкции кладётся в стек возврата в качестве адреса, который будет исполняться по возвращении из прерывания, после чего разрешается обработка самого прерывания. До тех пор, пока потоковые инструкции хранят свои рабочие параметры в стеке ( что достаточно просто в случае операций, подобных перемещению блока данных ), такой метод требует очень небольших дополнительных затрат при прерываниях, и не требует их вовсе при нормальном исполнении программы.
==148
6.5.2 «Упрощённые» прерывания
Давайте рассмотрим требования к сохранению состояния для трёх различных категорий прерываний: быстрых прерываний, облегченных потоков в многозадачной среде и полного переключения контекста.
Чаще всего при работе встречаются быстрые прерывания. Они могут заниматься обновлением счётчика времени или копированием байта данных из входного порта в буферную память. При работе с такими прерываниями обычные машины сохраняют пару-тройку регистров в системной памяти, чтобы освободить рабочее место в регистровом файле. В стековых машинах ничего сохранять не требуется. Обработчик прерывания может просто положить свои данные на вершину стека, никак не меняя информацию прерванной программы. Таким образом, при быстрых прерываниях у стековых машин нет никаких накладных расходов на сохранение состояния.
Облегченные потоки - отдельные задачи, похожие по поведению на только что описанные прерывания. Они получают преимущества многозадачности без расходов на запуск и останов полновесных процессов. В стековых машинах облегченные потоки могут создаваться простым ограничением на длину цепочки команд, которую можно выполнить до возврата управления планировщику. Такая схема может быть названа невытесняющей или кооперативной многозадачностью. Если каждая задача начинает и заканчивает работу с пустым стеком, то нет и расходов на переключение контекста. Такой вариант многозадачности ничего не стоит, так как возврат управления происходит на логических границах программы и, возможно, в такие моменты стек был бы пуст в любом случае.
Их этих двух примеров становится ясно, что обработка прерываний и лёгкопоточная многозадачность почти не имеют накладных расходов в стековых архитектурах. Единственным открытым вопросом остаётся полновесная вытесняющая схема, которая подразумевает переключение контекста.
6.5.3 Переключения контекста
Накладные расходы на переключение контекста обычно приводятся в качестве причины того, почему «стековые машины не подходят для многозадачности». Аргументы, подкрепляющие это мнение, часто основываются на необходимости сохранения огромных объёмов данных из стековых буферов в системной памяти. Но тезис о том, что в условиях многозадачности стековые машины чем-то хуже других архитектур совершенно неверен.
Переключение контекста потенциально весьма трудоёмкая операция для вычислительной системы любой архитектуры. Скрытое снижение производительности в RISC и CISC компьютерах сразу после переключения от увеличения количества кэш-промахов может сделать такое переключение дороже, чем рассчитывал проектировщик. С учётом того, что RISC машины используют большие регистровые файлы, им приходится сталкиваться с теми же проблемами, что и стековым компьютерам. Дополнительной неприятностью в RISC машинах является прямой доступ к регистрам, требующий сохранения их всех ( или использования аппаратных решений, помечающих используемые регистры ), в то время как стековые машины могут спокойно сохранить только активную область стекового буфера. [* Знать бы ещё как её помечают ] .
==149
6.5.3.1 Эксперименты с переключением контекста
Табл. 6.7a и 6.7b показывает число циклов памяти, которые тратятся на сохранение и восстановление содержимого стека программ на FORTH в многозадачной среде, полученные при трассировке на симуляторе. В симуляции участвовали программы «Queen», «Hanoi» и «Quick-sort». Для сохранения приемлемого времени трассировки в «Queen» и «Hanoi» использовались небольшие значения N . Измерялись эффекты от переполнений и антипереполнений стека, а также переключений контекста, так как в условиях многозадачности все они тесно взаимосвязаны.
Табл. 6.7a и рис. 6.4 показывают результаты для стека со страничным управлением. Обозначение «xxx CLOCKS/SWITCH» указывает число тактов между переключениями контекста. При 100 тактах число затрачиваемых на обслуживание стека циклов памяти сначала снижается по мере роста объёма буферов. Снижение затрат является следствием уменьшения частоты подкачки буфера при обращении программы к стеку. Но после того как размер буфера переваливает границу в восемь элементов, трафик начинает увеличиваться, потому что при переключениях задач происходит постоянное сохранение и восстановление растущих в объёме буферов.

Рис. 6.4 Затраты на обслуживание стека со страничным управлением
Следует отметить поведение программы при 500 тактах между переключениями задач. Даже при таком высоком значении ( которое соответствует 20'000 переключений в секунду для 10 MHz процессора и является чрезмерно высоким для практического использования ), затраты составляют около 0.08 такта на инструкцию при объёме буфера более 12 элементов. Так как без переключений одна инструкция занимала в среднем 1.688 такта [* состоит из двух микроинструкций минимум ] , полученные данные соответствуют 4.7% расходов на переключение. Для 10'000 тактов между переключениями ( 1 миллисекунда между сменой контекста ) затраты составляют менее 1%.
Как получаются столь скромные цифры? Одной из причин служит средняя используемая глубина стека, составляющая даже для указанных сильно рекурсивных программ всего 12.1 элемента. Это означает, что в стеке никогда не бывает очень много данных и сохранять требуется совсем небольшой объём. Участвовавшая в эксперименте стековая машина фактически имеет меньший объём сохраняемых при переключении данных, чем 16-регистровый CISC процессор.
Табл. 6.7(a) Страничное управление буфером
Табл. 6.7b и рис. 6.5 показывают результаты аналогичных экспериментов с использованием алгоритма управления стеком по запросу. Данные говорят, что подъём графика на границе 12 элементов для 100 тактов отсутствует почти полностью. Это происходит, потому что не проводится принудительная закачка содержимого буфера при восстановлении состояния. Вместо этого заполнение происходит в процессе работы по прямому запросу. Для разумных частот смены задач ( менее 1000 в секунду ) алгоритм с обслуживанием по запросу работает чуть лучше, чем страничная стратегия, но разница не ошеломляет.
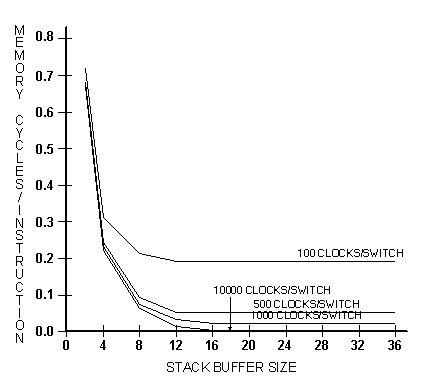
Рис. 6.5 Затраты на обслуживание стека с управлением по запросу
Табл. 6.7(b) Управление буфером по запросу
6.5.3.2 Многозадачность при большом числе стеков
==150
==151
Для стековых машин существует решение, позволяющее избавиться даже от только что показанных незначительных затрат. Вместо использования одного большого стека для всех программ для высокоприоритетных или чувствительных ко времени участков программы можно назначить отдельное стековое пространство. То есть каждый процесс использует отдельные указатели стека и границы, чтобы выгородить себе собственную стековую память. В момент переключения планировщик просто сохраняет указатель стека, так как границы ему известны и так. После загрузки новых значений указателей стека и границы новая задача готова к работе. На обновление содержимого буферов время не тратится вовсе.
Объём потребной для большинства программ стековой памяти обычно довольно мал. Более того, для коротких критичных ко времени процессов его величину можно задать при проектировании. Таким образом, даже средний 128-элементный буфер может быть поделён между четырьмя задачами по 32 элемента на каждую. Если в системе будет больше четырёх процессов, один из буферов можно превратить в низкоприоритетный стек общего пользования, который будет разделяться между всеми низкоприоритетными задачами с использованием схемы сохранения-восстановления буфера.
Из представленных рассуждений понятно, что утверждение о неэффективности многозадачности на стековых процессорах из-за чрезмерного объёма сохраняемых данных о состоянии, не соответствует действительности. На самом деле, во многих случаях стековые машины лучше, чем все прочие архитектуры, подходят для обработки прерываний и многозадачности.
==152
Независимое исследование Hayes и Fraeman ( 1988 ) показало похожие результаты по затратам на обновление буферов и переключение контекста для FRISC 3 .
==152
