
6.4 Вопросы управления стеками
==139
Производительность стековых машин прямо зависит от скорости работы стеков, обращение к которым происходит в каждой инструкции. По этой причине характеристики и особенности использования стековой памяти приобретают первостепенное значение. Вопрос формулируется следующим образом: «сколько стековой памяти следует разместить на кристалле для получения хорошей производительности»? Ответ на этот вопрос очень важен, так как он влияет на цену и производительность старших моделей процессоров, чья стековая память размещается на кристалле.
Столь же важным вопросом, особенно в условиях многозадачной среды, является способ управления стеками.
6.4.1 Экспериментальное определение размеров стека
Ответ на первый вопрос о размере внутреннего буфера проще всего получить на симуляторе, запуская программы с различными параметрами буферов. Симуляция позволяет замерить интенсивность операций обмена с памятью в случае возникновения проблем со стеком: при переполнении требуется переместить содержимое аппаратных стековых буферов в системную память, а при антипереполнении в обратном направлении.
Результаты симуляции, при которой контролировалось число циклов памяти, потраченных на сброс и восстановление стековых буферов для «Life», «Hanoi», «Frac», «Fib», «Math» и «Queens» даны в табл. 6.5 и на рис. 6.2 . Несмотря на то, что «игрушечные» тесты «Fib», «Hanoi» и «Queens» не похожи на обычные программы, все они имеют сильно рекурсивную природу и могут служить примерами самых ресурсоёмких стековых программ.
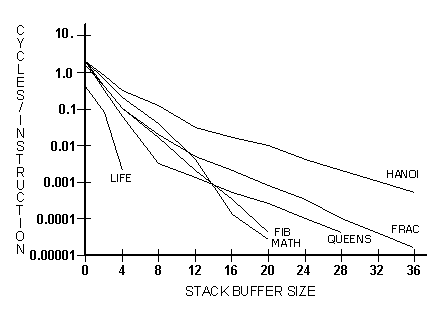
Рис. 6.2 Число сбросов буфера стека данных
==140
Табл. 6.5. Число циклов обращения к памяти, потраченных на обновление содержимого стековых буферов
==141
Алгоритм сброса данных откачивает по одному элементу стекового буфера на каждую операцию сохранения в стеке, когда он полон, и восстанавливает один элемент на каждую операцию удаления из стека, когда он пуст. Симуляция предполагает, что сброс буферов производится аппаратно со скоростью один элемент за один цикл обращения к памяти. При симуляции использовался набор инструкций RTX 32P , и поэтому каждая директива получилась приблизительно в два раза насыщеннее, чем можно наблюдать в процессорах с постоянной системой команд, подобных RTX 2000 . Полученные цифры соответствуют числу циклов памяти, а не количеству микроциклов. Целью симуляции была демонстрация наилучшего ожидаемого варианта, который для большинства реализаций оказывается в три-четыре раза менее требователен к ресурсам.
Совершенно неожиданно программа «Frac» оказалась почти столь же требовательной к объёму стека, как «Hanoi». Это происходит, потому что на каждом шаге рекурсивного алгоритма разделения точек «Frac» кладёт в стек данных шесть элементов. Очевидно, что любая рекурсивная программа способна загружать в стек массу данных.
Хорошим известием является экспоненциальное уменьшение трафика при переполнении/антипереполнении по мере роста объёма стека для всех программ. При размере стековых буферов в 20 элементов даже у «Hanoi» сброс буферов занимает менее 1% от числа инструкций [* обращений к программной памяти при выборке инструкций ] . На практике при объёме в 32 элемента переполнения исключаются почти для всех программ.
==142
Табл. 6.6. Число циклов обращения к памяти, потраченных на сброс стека возврата
==143
В табл. 6.6 и на рис. 6.3 приводятся данные симуляции сброса содержимого стека возврата для тех же программ. Результаты аналогичные, за исключением данных для «Math», обнаруживших его интенсивное использование. Это происходит, потому что для облегчения переносимости библиотека написана в виде многочисленных модулей и использует большое число глубоко вложенных процедур. Кроме того, она хранит в стеке возврата временные переменные для работы с 48-битными данными на 16-разрядных процессорах.
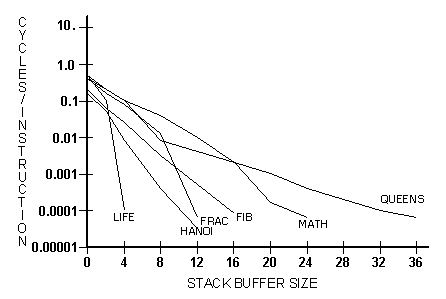
Рис. 6.3 Число сбросов буфера стека возврата
6.4.2 Обработка исключений по переполнению
Теперь нужно выяснить, как следует обрабатывать переполнения стека в процессе работы программы. Возможны четыре подхода: считать, что переполнений не может быть и рассматривать их как катастрофическую ситуацию; использовать схему управления, работающую по запросу; использовать страничное управление; использовать кэш данных. У каждого варианта есть сильные и слабые стороны.
6.4.2.1 Очень большая стековая память
Самый простой способ решения проблем со стеком - считать, что их быть не может. И хотя не первый взгляд он выглядит довольно глупо, достоинства у него есть. Самое приятное, что даёт такая стратегия - производительность системы полностью предсказуема ( так как не расходуется на сброс/восстановление содержимого стеков ) и не требуется дополнительных схем управления.
Подход с использованием очень большой стековой памяти, чтобы избежать переполнений, взят на вооружение в MISC M17 . В этом процессоре переполнение возникает, только когда полностью исчерпана системная память. В NC4016 проблема решается использованием быстрой внешней стековой памяти, которую можно наращивать до глубины несколько тысяч элементов. Оба процессора проблемы переполнения игнорируют. Цена, которая при этом платится, - компромисс между скоростью и объёмом внешней памяти с одной стороны и быстродействием процессора с другой.
==144
Рассматривать переполнения, как катастрофические системные события, требующие отладки программы, можно и в случае использования небольших внутрипроцессорных стеков. В этом случае программисту просто объявляется, что у него есть «X» элементов стека, и он отвечает за непревышение этого предела. В том случае, когда речь идёт о написании маленьких и простых программ, а «X» не меньше 16..32 элементов, такой подход весьма практичен. Он используется в WISC CPU/16 , имеющем для упрощения аппаратуры 256-элементный стек.
6.4.2.2 Одноэлементная схема управления стеком, работающая по запросу
Если предположить, что переполнения будут происходить на регулярной основе, то самым привлекательным с конструктивной точки зрения будет использование схемы управления, которая будет перемещать отдельные элементы между стеком и памятью по запросу.
Для реализации этой идеи следует организовать внутренний стек в виде кольцевого буфера с указателями головы и хвоста. Кроме того, требуется указатель на верхний элемент той части стека, которая располагается в системной памяти. Каждый раз при возникновении переполнения самый нижний элемент буфера сбрасывается в память, освобождая место. При антипереполнении элемент копируется из памяти в буфер. Эта техника привлекательна тем, что процессор не трогает без необходимости содержимое стека, обеспечивая минимальный трафик.
Возможным улучшением этой схемы будет постоянное поддержание зазоров на концах буфера из нескольких пустых и нескольких полных ячеек. Это можно делать, забирая неиспользуемые циклы памяти и сокращая, тем самым, число пауз при переполнении. К сожалению, подобные улучшения для стековых машин бесполезны, так как шина памяти в них используется полностью, инструкции и данные считываются без какого-либо зазора для работы схемы управления стеком [* это свидетельствует о высокой степени сбалансированности конструкции и оптимальности её использования ] .
Преимуществом обслуживания стека по запросу является возможность очень эффективного использования элементов буфера. Такая схема пригодна для проектов, в которых площадь кристалла имеет первостепенное значение. Дополнительным преимуществом является «размазывание» стековых переполнений по всему времени исполнения с максимум двумя такими событиями на инструкцию в случае сброса стека данных в момент антипереполнения при возврате из подпрограммы [* а в других случаях, сколько переполнений одновременно может быть у двух стеков ? ] В цену получаемой производительности входит довольно сложная управляющая аппаратура и три счётчика на каждый стек.
Схема управления FRISC 3 похожа на обслуживание по запросу. Проектировщики провели заметные исследования в этой области. Более универсальная версия алгоритма, именуемая «cutback-K» была предложена Hasegawa & Shigei ( 1985 ). Проблемы управления буферами верхних элементов стека RISC машин обсуждаются у Stanley & Wedig ( 1987 ).
==145
6.4.2.3 Страничная схема управления стеком
Альтернативой аппаратному решению может служить схема с программным прерыванием по переполнению стека, при котором собственно сбросом содержимого стека занимается программа-обработчик прерывания. Такой подход требует меньше аппаратной обвязки, но, чтобы уменьшить интенсивность прерываний, ему нужны стеки несколько большего размера, чем в схеме обслуживания по запросу.
Схема использует регистры, указывающие на адреса неподалёку от верхней и нижней границы наблюдаемой области стека. Когда на очередной инструкции указатель стека становится меньше, чем регистр антипереполнения, блок объёмом в половину буфера копируется из системной памяти. Если указатель стека превысит значение регистра переполнения, блок размером в половину буфера сбрасывается в системную память.
В системах с разделением времени страничная схема позволяет назначать отдельные секции большой стековой памяти для использования отдельными процедурами. В этом случае стеки должны делаться не в виде кольцевых буферов, а в виде секций в специальной памяти. Переполнение будет вызывать копирование в системную память блока, равного половине стекового буфера, с последующим переназначением освободившейся половины в начало области стекового буфера [* в качестве свободного места для расширения стека ] .
Затраты на страничное управление в сравнении с обслуживанием по запросу. Во-первых, удваивается время, затрачиваемое на перемещение данных. Во-вторых, требуются в два раза большие буфера, которые позволяют гарантировать такое же количество последовательных операций сохранения в стеке между переполнениями. На практике увеличение размера буферов требуется редко.
Интересным способом использования данного метода является провозглашение стиля программирования, при котором переполнения считаются маловероятными и нежелательными, так как 32 элемента буфера «..должно быть достаточно для каждого». Страничный метод обеспечивает недорогую аппаратную поддержку для плавного снижения производительности программы, нарушающей конвенцию по использованию буфера. При таком подходе неоптимальная программа работает, тем не менее, правильно ( просто медленно ) а операционная система может сформировать предупреждение с указанием нарушителя.
Страничное управление стеком используется в процессорах RTX 2000 и RTX 32P .
6.4.2.4 Ассоциативный кэш
Метод управления стеком, используемый многими обычными процессорами, заключается в использовании стандартного кэша данных, отображённого на адресное пространство программы. Данный метод приводит к существенному усложнению аппаратуры, но по сравнению с уже описанными решениями не обеспечивает никаких преимуществ для стековых машин, так как в них обращение происходит к компактно расположенным элементам [*] . Метод обеспечивает преимущество при сохранении в «стеке» структур данных переменной длины таких, как строки или записи языков Си или Ada.
[* «..since stack machines do not skip about much in accessing their stack elements» - кэш хорошо работает при частых обращениях к одним и тем же элементам, разбросанным по адресному пространству, например, при работе со строками или полями структур ].
==146
Некоторые публикации, в которых обсуждаются проблемы управления стеком: Blake ( 1977 ), Hennesy ( 1984 ), Prabhala & Sethi ( 1977 ) и Sites ( 1979 ).
==146
