
3.2 Классическая стековая машина
==33
Перед тем, как погрузиться в детальное рассмотрение реальных конструкций MS0 и ML0 , следует создать эталон для сравнения. Для этого мы разберём устройство классической ML0 машины. Представляемая конструкция проста настолько, насколько это необходимо, чтобы стать отправной точкой для дальнейших сравнений.
3.2.1 Блок-схема
На рис. 3.1 представлена блок-схема «Классической Стековой Машины». Каждый блок на схеме представляет часть машинной логики, соответствующей минимально необходимому компоненту конструкции ML0 . В число таких компонентов входят: «шина данных» ( data bus ), «стек данных» ( DS ), «стек адресов возврата» или просто «стек возврата» ( RS ), «арифметическо-логическое устройство» ( ALU ) с регистром «вершина стека» ( TOS ), «счетчик программы» ( PC ), «программная память» с «регистром адреса памяти» ( MAR ), управляющая логика с «регистром инструкций» ( IR ) и секция «ввода-вывода» ( I/O ).
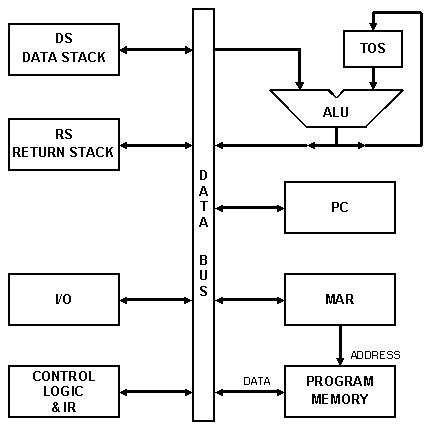
Рис. 3.1 Классическая Стековая Машина
3.2.1.1 Шина данных
Для простоты в «Классической Стековой Машине» есть только одна шина, соединяющая компоненты системы - Data bus. Реальные процессоры могут иметь больше одного канала передачи данных, чтобы распараллелить вычисления и операции выбора инструкции. В «Классической Стековой Машине» шина данных позволяет иметь один передающий и один принимающий блок в любом отдельном рабочем цикле.
3.2.1.2 Стек данных
==34
Стек данных ( DS ) - память, имеющая встроенный механизм реализации стека ( LIFO ). Типовой реализацией служит обычная память с реверсивным счётчиком, используемым для формирования адреса. Стек данных позволяет выполнять две операции: «PUSH» и «POP». «PUSH» - заводит на вершине стека новую ячейку и записывает в неё значение с шины данных. «POP» - выдаёт значение из ячейки на вершине стека на шину данных, после чего удаляет ячейку, открывая следующую за ней для дальнейших операций.
3.2.1.3 Стек адресов возврата
Стек адресов возврата ( RS ) или просто стек возврата - обычный LIFO стек, реализованный так же, как и стек данных. Единственное отличие - стек возврата используется для сохранения адресов возврата из подпрограмм вместо аргументов инструкций.
3.2.1.4 АЛУ и регистр вершины стека
==35
Функциональный элемент АЛУ выполняет арифметические и логические вычисления над парой верхних элементов стека данных. Первым операндом является регистр «вершина стека» ( TOS ) - одноэлементный буфер, расположенный внутри АЛУ. Второй операнд - верхнее слово аппаратного стека. Программисту TOS виден как верхний элемент стека данных, а верхнее слово аппаратного стека - как второй элемент стека. Такая схема позволяет использовать для стека данных однопортовую память, допуская при этом действия, подобные сложению, над двумя элементами стека одновременно.
АЛУ поддерживает стандартные элементарные операции, необходимые любому компьютеру. В иллюстративных целях этот набор состоит из сложения, вычитания, логических функций ( «И», «ИЛИ», «ИСКЛЮЧАЮЩЕЕ-ИЛИ» ) и операции проверки на нуль. В соответствии с целями разработки все вычисления идут над целыми числами, но в общем случае нет никаких причин, препятствующих добавлению в АЛУ арифметики с плавающей запятой.
3.2.1.5 Счётчик команд
Счётчик команд ( PC ) содержит адрес следующей исполняемой инструкции. Для выполнения переходов PC может загружаться с шины данных или просто увеличиваться для выборки очередной инструкции из программной памяти.
3.2.1.6 Программная память и регистр адресации памяти
Блок программной памяти состоит из регистра адресации памяти ( MAR ), в который записывается адрес нужной ячейки, и какого-то количества оперативной памяти. В следующем процессорном цикле указанная ячейка или считывается, или записывается через системную шину данных.
3.2.1.7 Ввод/вывод
Как и в большинстве концептуальных разработок, вопрос связи с внешним миром детально не рассматривается. Достаточно сказать, что в системе присутствуют предназначенные для выполнения этой задачи ресурсы - блок ввода/вывода ( I/O ).
3.2.2 Операции над данными
Табл. 3.1 показывает минимальный набор операторов «Классической Стековой Машины». Данный набор выбран из соображений наглядности использования модели и, очевидно, не соответствует задачам эффективного исполнения программ. В частности, операции умножения, деления и сдвига для простоты опущены. Программная нотация взята из языка FORTH ( см. §3.3 ), чтобы обеспечить преемственность обсуждения наборов инструкций в следующих частях книги. Следует обратить внимание на интенсивное использование в языке FORTH специальных символов, таких как «!» ( произносится в FORTH как «store» - сохранить ) и «@» ( произносится как «fetch» - выбрать ).
Табл. 3.1 Набор инструкций Классической Стековой Машины
3.2.2.1 Обратная польская запись
Стековые машины проводят действия с данными, используя постфиксные операции. Такие операции обычно называются «обратные польские» по аналогии с «обратной польской записью» ( RPN ), часто используемой для описания постфиксных операций. Их особенностью является то, что операнды идут впереди символа операции. Возьмём, например, выражение в обычной ( инфиксной ) записи:
==36
(12 + 45) * 98
В этом выражении скобки используются для того, чтобы операция сложения была выполнена перед умножением. В их отсутствие действует подразумеваемое старшинство операций. Например, без скобок умножение будет выполняться перед сложением. В постфиксной записи выражение из примера выше выглядело бы следующим образом:
98 12 45 + *
В постфиксной записи операторы выполняются над ближайшими видимыми операндами с использованием для вычислений стека, наличие которого подразумевается. В предложенном примере числа 98 , 12 и 45 кладутся в стек, как показано на рис. 3.2 . После этого оператор «+» работает с двумя верхними элементами стека ( а именно 45 и 12 ), оставляя в стеке результат 57 . Затем оператор «*» обрабатывает два новых верхних элемента стека: 57 и 98 , оставляя в стеке 5586 .
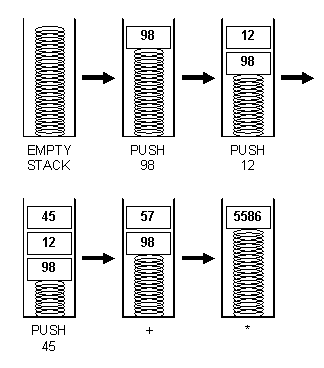
Рис. 3.2 Пример стековой операции
==37
Выражения в постфиксной записи получаются компактнее, по сравнению с инфиксной, так как не требуют ни правил старшинства операторов, ни скобок. Они гораздо лучше подходят под нужды компьютеров. На самом деле, компиляторы, естественно, переводят инфиксные выражения, написанные на языке подобном Си или FORTRAN, в постфиксные машинные коды, иногда используя явное распределение регистров вместо стека для вычисления выражений.
«Классическая Стековая Машина» спроектирована так, чтобы выполнять постфиксные операции непосредственно, не обременяя компилятор регистровой бухгалтерией.
3.2.2.2 Арифметические и логические операторы
В соответствии с требованиями по обеспечению базовых вычислений «Классической Стековой Машине» нужны арифметические и логические операторы. В этом и последующих разделах передача данных между регистрами для каждой инструкции будет поясняться псевдокодом. Например, первая операция «сложение».
==38
| Операция: | + | |
| Стек: | N1 N2 → N3 | |
| Описание: | Складывает N1 и N2 и возвращает сумму N3 | |
| Псевдокод: |
TOSREG ← TOSREG + POP(DS) |
Для операции «+» два верхних элемента стека данных N1 и N2 извлекаются и складываются, а результат N3 кладётся обратно в стек. С точки зрения реализации это означает выталкивание значения из стека данных - DS ( что даёт N1 ) и прибавление его к TOSREG , содержащего N2 . Результат кладётся обратно в TOSREG , оставляя N3 на вершине стека данных. Элемент DS , доступ к которому осуществляется операцией «POP(DS)», видимый программисту, как второй от вершины элемент стека, является на самом деле верхним элементом аппаратного стека данных. Операция «POP(DS)» связана с обозначением TOSREG , как верхнего элемента стека , сообразно тому, как он виден пользователю. Отметим, что одноэлементный стековый буфер TOSREG позволяет избежать выталкивания элемента N2 и последующего сохранения элемента N3 .
| Операция: | - | |
| Стек: | N1 N2 → N3 | |
| Описание: | Вычитает N2 из N1 и возвращает разность N3 | |
| Псевдокод: |
TOSREG ← POP(DS) - TOSREG |
| Операция: | AND | |
| Стек: | N1 N2 → N3 | |
| Описание: | Выполняет побитное логическое умножение N1 и N2 и возвращает результат N3 | |
| Псевдокод: |
TOSREG ← TOSREG and POP(DS) |
| Операция: | OR | |
| Стек: | N1 N2 → N3 | |
| Описание: | Выполняет побитное логическое сложение N1 и N2 и возвращает результат N3 | |
| Псевдокод: |
TOSREG ← TOSREG or POP(DS) |
| Операция: | XOR | |
| Стек: | N1 N2 → N3 | |
| Описание: | Выполняет «сложение по модулю 2» N1 и N2 и возвращает результат N3 | |
| Псевдокод: |
TOSREG ← TOSREG xor POP(DS) |
Очевидно, что буферный регистр верхнего элемента стека экономит заметный объём работы при выполнении этих операций.
==39
3.2.2.3 Операторы для работы со стеком
Одна из проблем машин классической стековой архитектуры состоит в том, что они могут проводить арифметические операции только с двумя верхними элементами стека. Таким образом, на подготовку операндов для вычисления приходится тратить дополнительные инструкции. Следует, естественно, отметить, что некоторые регистровые машины тоже тратят много дополнительных инструкций, перемещая данные между регистрами в процессе подготовки к вычислениям и, таким образом, вопрос о том какой подход лучше становится чуть более запутанным.
Нижеследующие инструкции предназначены для работы с элементами стека.
| Операция: | DROP | |
| Стек: | N1 → | |
| Описание: | Удаляет N1 из стека | |
| Псевдокод: |
TOSREG ← POP(DS) |
Здесь и далее в описаниях инструкций используется запись, подобная «TOSREG ← POP(DS)». В ходе выполнения этой операции данные из стека выставляются на шину данных, затем проходят через АЛУ, где над ними совершается какая-либо пустая операция ( например, сложение с нулём ), чтобы результат положить в регистр вершины стека.
| Операция: | DUP | |
| Стек: | N1 → N1 N1 | |
| Описание: | Делает копию N1 и помещает её в стек | |
| Псевдокод: |
PUSH(DS) ← TOSREG |
| Операция: | OVER | |
| Стек: | N1 N2 → N1 N2 N1 | |
| Описание: | Делает копию второго сверху элемента стека N1 и помещает её в стек | |
| Псевдокод: |
PUSH(RS) ← TOSREG ( Положить N2 в RS )
TOSREG ← POP(DS) ( Положить N1 в TOSREG, получить копию
N1, т.е. первый элемент в TOS )
PUSH(DS) ← TOSREG ( Сохранить N1 в DS, т.е. восстановить
N1 в качестве третьего элемента )
PUSH(DS) ← POP(RS) ( Сохранить N2 - второй элемент в DS,
минуя TOS ) |
Если смотреть только на описание, то инструкция «OVER» выглядит довольно просто. На самом деле она осложняется необходимостью временно сохранять где-нибудь мешающий элемент N2 . В реальных процессорах вводят один-два регистра временного хранения, чтобы уменьшить число вспомогательных операций для «OVER», «SWAP» и других инструкций, переставляющих элементы стека.
==40
| Операция: | SWAP | |
| Стек: | N1 N2 → N2 N1 | |
| Описание: | Меняет местами два верхних элемента стека | |
| Псевдокод: |
PUSH(RS) ← TOSREG ( Сохранить N2 в RS ) TOSREG ← POP(DS) ( Поместить N1 в TOSREG ) PUSH(DS) ← POP(RS) ( Сохранить N2 в DS ) |
| Операция: | >R ( Читается как «to R» ) | |
| Стек: | N1 → | |
| Описание: | Кладёт N1 в стек возврата | |
| Псевдокод: |
PUSH(RS) ← TOSREG TOSREG ← POP(DS) |
Инструкция «>R» и её дополнение «R>» позволяет перемещать элементы данных между стеками данных и адресов возврата. Эти команды используются для временного перемещения верхних элементов в стек возврата для получения доступа к данным, лежащим глубже двух первых уровней стека.
| Операция: | R> ( Читается как «R from» ) | |
| Стек: | → N1 | |
| Описание: | Извлекает верхний элемент из стека возврата и кладёт его в качестве N1 в стек данных | |
| Псевдокод: |
PUSH(DS) ← TOSREG TOSREG ← POP(RS) |
3.2.2.4 Чтение и запись памяти
Если все арифметические и логические операции проводятся только над элементами стека, то должен существовать способ загрузки в стек данных или выгрузки данных из стека для сохранения в памяти. «Классическая Стековая Машина» использует простую архитектуру вида «загрузить/сохранить» и поэтому использует одну инструкцию загрузки «@» и одну инструкцию сохранения «!».
У инструкций отсутствует поле операнда, а адрес памяти берётся из стека, что облегчает доступ к членам структуры данных, так как указатель в стеке можно индексировать поэлементно. Инструкции требуют двух циклов обращения к памяти: один для команды и один для данных.
==41
| Операция: | ! ( Читается как «store» ) | |
| Стек: | N1 ADDR → | |
| Описание: | Сохраняет N1 по адресу ADDR в программной памяти | |
| Псевдокод: |
MAR ← TOSREG MEMORY ← POP(DS) TOSREG ← POP(DS) |
| Операция: | @ ( Читается как «fetch» ) | |
| Стек: | ADDR → N1 | |
| Описание: | Считывает значение из программной памяти по адресу ADDR и возвращает его в N1 | |
| Псевдокод: |
MAR ← TOSREG TOSREG ← MEMORY |
3.2.2.5 Символьные константы
Должен существовать какой-либо способ размещения в стеке констант. Инструкции, которые это делают, называются «символьными» , а в регистровых архитектурах - «загружающими непосредственное значение» . Литеральные инструкции используют два соседних программных слова: первое для кода инструкции, а второе для константы, и, соответственно, требуют двух циклов обращения к памяти.
| Операция: | [LIT] | |
| Стек: | → N1 | |
| Описание: | Рассматривает следующее программное слова как целое число и сохраняет его в стеке в качестве N1 | |
| Псевдокод: |
MAR ← PC ( Адрес константы )
PC ← PC + 1
PUSH(DS) ← TOSREG
TOSREG ← MEMORY
|
Такая реализация предполагает, что PC указывает на адрес памяти, следующий после кода операции.
3.2.3 Выполнение инструкций
До настоящего момента механизм выборки команд из памяти не учитывался. Обычно под ним подразумевается стандартная последовательность из выборки, декодирования и исполнения инструкции.
3.2.3.1 Счётчик команд
==42
Счётчик команд ( PC ) - регистр, содержащий адрес следующей исполняемой инструкции. В процессе выборки команды PC автоматически увеличивается, чтобы указывать на следующее слово в памяти. Инструкции ветвления или вызова подпрограммы загружают в счётчик команд новый адрес, на который нужно выполнить переход.
Внутренняя последовательность действий, выполняемая при обработке каждой команды, выглядит так:
| Операция: | [Fetch next instruction] | |
| Стек: | ||
| Описание: | Выбирает следующую инструкцию | |
| Псевдокод: |
MAR ← PC IR ← MEMORY PC ← PC + 1 |
3.2.3.2 Условные переходы
Чтобы иметь возможность принимать решения машина должна быть способна делать условные переходы. В «Классической Стековой Машине» используется самый простой из всех возможных способов - переход выполняется в случае равенства верхнего элемента стека нулю. Такой подход делает ненужными коды условий, позволяя, тем не менее, реализовать все управляющие программные конструкции.
| Операция: | [IF] | |
| Стек: | N1 → | |
| Описание: | В том случае, когда значение N1 ложно ( равно нулю ) в PC загружается адрес из следующего программного слова, в противном случае в PC загружается адрес очередной команды | |
| Псевдокод: |
if TOSREG is 0
MAR ← PC
PC ← MEMORY
else
PC ← PC + 1
endif
TOSREG ← POP(DS)
|
3.2.3.3 Вызов подпрограмм
И, наконец, «Классическая Стековая Машина» должна иметь возможность вызова подпрограмм. Наличие специального стека, выделенного под адреса возврата, позволяет вызывать подпрограммы, просто сохраняя в стеке текущее состояние счётчика команд и загружая в него новое значение. Мы будем считать, что формат инструкции вызова подпрограммы позволяет указать полный адрес процедуры в одном машинном слове, и опустим реальный механизм извлечения из него поля адреса. Реальные процессоры, рассматриваемые в последующих частях книги, предлагают различные способы решения этой задачи при весьма умеренных аппаратных затратах.
Возврат из подпрограммы выполняется простым выталкиванием с вершины стека адреса возврата и помещения его в счётчик команд. Из-за того, что данные хранятся в отдельном стеке, никаких дополнительных действий с указателями или памятью при вызове подпрограмм не требуется.
==43
| Операция: | [CALL] | |
| Стек: | ||
| Описание: | Выполняет вызов подпрограммы по адресу, расположенному в следующем программном слове | |
| Псевдокод: |
PUSH(RS) ← PC ( Сохранить адрес возврата )
PC ← IR ADDRESS FIELD |
| Операция: | [EXIT] | |
| Стек: | ||
| Описание: | Выполняет возврат из подпрограммы | |
| Псевдокод: |
PC ← POP(RS) |
3.2.3.4 Постоянные и подгружаемые наборы инструкций
Для сохранения простоты, описание «Классической Стековой Машины» свободно от рекомендаций по разработке, но, всё же, следует рассмотреть основные сложности, возникающие при воплощении реальных конструкций. Одним из вопросов является выбор между постоянным и подгружаемым набором инструкций. Введение в технику реализации постоянных и подгружаемых наборов можно найти в Koopman ( 1987a ).
Конструкции с постоянным набором обычно быстрее и компактнее. Ценой повышения производительности является бОльшая сложность схемы декодирования и серьёзный риск полной переделки управляющей логики при изменении требований к набору команд ближе к концу срока разработки.
Формат инструкций в стековых машинах [* MS0/ML0 ] очень несложен - только код операции. Кроме того, он совершенно свободен от массы возможных сочетаний операндов и типов. Это одна из причин относительной простоты и прямолинейности конструкции с постоянным набором команд.
Дополнительным плюсом является тот факт, что в 16- и более разрядных машинах ширина слова заметно больше, чем несколько бит, необходимых для кодирования всех возможных операций. С учётом этого факта модели с постоянным набором используют частично декодированный формат инструкций, позволяющий упростить аппаратуру и увеличить её гибкость. Частично декодированные ( они же не полностью кодированные или «раскодированные» ) инструкции имеют формат, похожий на микрокод, в котором отдельные поля команды отведены под определённые задачи. Это позволяет комбинировать в одном машинном слове несколько независимых операций ( таких, как «DUP» и «[EXIT]» ).
==44
Несмотря на то, что 16-битные инструкции кажутся откровенно избыточными, их постоянная длина упрощает схему декодирования и позволяет уместить вызов подпрограммы в одном машинном слове. Самый несложный способ кодировки - просто установить самый старший [* или самый младший ] бит в «0» для кода вызова подпрограммы ( оставляя на адрес 15 разрядов ) и в «1» для всех остальных кодов операций ( на поле кода операции остаются те же 15 разрядов ). В общем случае скоростные преимущества постоянной длины команд в сочетании с возможностью комбинировать несколько операций в одном машинном слове делает выбор фиксированной длины обоснованной. Первой стековой машиной с постоянным набором команд и раскодированным форматом инструкций была модель NC4016 фирмы Novix.
Все эти преимущества жёсткого декодирования могут создать впечатление о бесперспективности применения подгружаемых наборов команд. Тем не менее, у микрокода есть некоторые полезные свойства.
Основным его преимуществом является гибкость. Из-за того, что большинство битовых комбинаций раскодированной инструкции не используются, архитектуры с микрокодированием могут задействовать меньше бит для указания возможных операций [*] , включая оптимизированные варианты, которые могут совершать несколько последовательных действий над стеком. Это позволяет освободить место для кодов, задаваемых пользователем. Машины с микрокодом могут иметь несколько сложных многотактовых пользовательских команд, которые будет невозможно реализовать в варианте с постоянным набором. Если часть или вся память микрокодов будет располагаться в оперативной памяти, то набор машинных команд можно будет подстраивать под каждого пользователя или даже под каждое приложение.
[*]
[* То есть использовать кодированные инструкции. В данном случае команда - это адрес начала последовательности микроопераций в специальной памяти микрокодов в той же мере, как КОП в машинах с постоянным набором является адресом элемента в таблице команд, «прошитых» в аппаратном декодере. А вот коды микроопераций уже являются декодированными ].
Одним из изъянов микрокода является то, что часто в попытке избежать снижения скорости при обращении к памяти микрокодов приходится использовать конвейер выборки микроинструкций. Это может привести к необходимости увеличения времени исполнения инструкции до двух тактов и более, в то время как конструкции и постоянным набором оптимизированы на исполнение за один такт.
С другой стороны это никакой не минус. Если использовать реальные соотношения скорости процессора и доступной по быстродействию памяти, то выяснится, что большинство процессоров может выполнить две внутренние операции со стеком за время одного обращения к памяти. Таким образом, и архитектуры с постоянным набором, и модели, использующие микрокод, могут исполнять инструкции за один цикл обращения к памяти . Более того, у моделей, использующих микрокод, есть гораздо больше возможностей для оптимизации кода за счёт того, что они могут вставить в два раза больше операций за один цикл обращения к памяти. [* Как видно из дальнейшего материала книги автор участвовал в нескольких проектах процессоров с микрокодовой архитектурой и, соответственно, не может не находить в них достоинств, сколь бы призрачными они ни казались ] .
С практической точки зрения, микрокод обычно реализуют в разработках на дискретной логике, поэтому они доминируют в одноплатных решениях. Большинство однокристальных моделей имеет постоянный набор команд.
3.2.4 Изменение состояния
Для приложений реального времени очень важен способ обработки процессором прерываний и переключения задач. Набор команд «Классической Стековой Машины» обходит этот проблему, поэтому мы поговорим о стандартных путях решения, чтобы иметь в дальнейшем основу для сравнения конструкций.
==45
Одной из проблем, отличающих машины с отдельной памятью для стеков, является большой объём сведений о состоянии, который требует сохранения где-либо в системной памяти при переключении задач. Мы рассмотрим способы, позволяющие избегать большей части подобных переключений. В Части _6 описываются методы, сокращающие накладные расходы при переключении.
3.2.4.1 Прерывания по переполнению и антипереполнению стека
Прерывания вызываются как исключительными событиями, например, переполнением стека, так и запросами на обслуживание ввода/вывода. Оба вида событий требуют быстрой реакции, не нарушающей логику работы текущего процесса.
Прерывания по переполнению/антипереполнению стека на данный момент самые частые исключительные ситуации в стековых машинах, и поэтому именно на них будет показано, как происходит обработка подобных событий.
Упомянутые исключения возникают в момент исчерпания всего объёма аппаратной стековой памяти. Реагировать можно по-разному: не предпринимать никаких действий и позволить программе завершиться аварийно ( самое простое в реализации, но и самое бесполезное решение [*] ), остановить программу с сообщением о фатальной ошибке и, наконец, переместить часть содержимого стека в системную память, чтобы продолжить исполнение. Понятно, что последний вариант даёт больше всего возможностей, но остановка по ошибке проще в исполнении и в некоторых случаях может быть допустима.
[*]
[* Почему обязательно «бесполезное»? Вон люди используют - §6.4.2.1 ].
Кроме того, так же могут обрабатываться и другие исключения, например, ошибка чётности памяти.
Исключительные ситуации могут требовать для своей обработки много времени, но в ходе разрешения все они должны сохранять состояние прерванной задачи неизменным, чтобы её исполнение можно было восстановить, если это возможно. Таким образом, исключения не должны требовать от процессора иных действий, кроме аппаратного вызова подпрограммы-обработчика.
3.2.4.2 Прерывания от подсистемы ввода/вывода
Обслуживание ввода/вывода достаточно частое событие, требующее быстрой обработки в системах реального времени. К счастью, такие прерывания обычно требуют немного вычислительных ресурсов и почти не требуют памяти. По этим соображениям в стековых архитектурах прерывания рассматриваются как аппаратно сформированные вызовы подпрограмм.
Такие вызовы кладут параметры в стек, проводят необходимые вычисления, после чего возвращают управление прерванной программе. Есть только одно требование: программа-обработчик прерывания не должна оставлять после себя «мусор» в стеке.
Накладные расходы на обработку прерываний в стековых машинах много ниже, чем в обычных архитектурах. Тому есть несколько причин. Нет нужды сохранять регистры, так как рабочее место в стеке заводится по мере надобности. Нет флагов состояния, требующих сохранения, так как для ветвления программ используются содержимое стека данных. Наконец, конвейер данных в большинстве стековых процессоров или отсутствует вовсе, или очень короткий, и штраф при сохранении его состояния при входе в прерывание отсутствует.
3.2.4.3 Переключение задач
Переключение задач происходит, когда процессор заменяет одну программу на другую, чтобы создать видимость одновременного их исполнения. Состояние программы, останавливаемой при переключении, должно быть сохранено, чтобы она могла продолжить работу позднее. Состояние программы, активируемой в ходе переключения, должно быть полностью восстановлено до момента возобновления её работы.
==46
Общепринятым способом достижения этой цели является использование таймера и переключение задач при каждом его отсчёте с возможным использованием алгоритмов приоритезации и планировки. В простых процессорах это может привести к заметному увеличению накладных расходов на сохранение и восстановление обоих стеков в памяти при каждом переключении контекста. В качестве решения проблемы можно предложить программную технику, использующую «легковесные» задачи, которые не требуют много места в стеке. Такие задачи могут класть свои параметры в стек поверх имеющегося содержимого и освобождать занятое место по завершении, исключая тем самым более дорогостоящее сохранение и восстановление стекового контекста более «тяжёлых» задач.
Другим решением может быть несколько наборов указателей стеков для нескольких задач, использующих общий блок стековой памяти.
==46
