
6.2 Архитектурные отличия от обычных машин
==117
Очевидным отличием стековых машин является использование 0-операндной адресации вместо обращения к регистрам или памяти. Данная особенность вместе с быстрым вызовом подпрограмм дают стековым компьютерам преимущество над обычными архитектурами в части компактности кода, простоты вычислительного ядра и системы, производительности процессора и однородности исполняемого кода.
==118
6.2.1 Размер программ
Расхожее мнение утверждает, что «память дешева», т.к. по мере развития технологии объём микросхем памяти растёт экспоненциально.
Проблема заключается в том, что размер задач, решаемых с помощью компьютеров, растёт, возможно, ещё быстрее. Это означает, что размер программ и обрабатываемых данных растёт даже быстрее, чем объём доступной памяти. Ситуацию усугубляет повсеместный отказ от машинных языков на всех уровнях создания программного обеспечения. В итоге программы становятся всё больше, хотя, конечно, производительность программистов возрастает.
Не удивительно, что взрывное увеличение сложности ведёт к кажущемуся противоречию, описываемому выражением: «программы стремятся использовать всю доступную память и ещё чуть-чуть». Объём доступной приложению памяти ограничивается стоимостью микросхем и площадью печатной платы. Кроме того, на него влияют конструктивные ограничения: потребляемая мощность, необходимость охлаждения и число слотов расширения системы ( эти параметры также подпадают под экономические ограничения ). Даже при неограниченном бюджете разработки, требования к нагрузочной способности и задержки распространения сигналов ограничивают максимальное число микросхем памяти, которое может использовать процессор. Небольшие размеры программ уменьшают стоимость подсистемы хранения, число компонентов, потребляемую мощность и могут делать использование небольших объёмов очень быстрого ОЗУ экономически оправданным. Дополнительными плюсами являются лучшая производительность виртуальной памяти ( Sweet & Sandman 1982 , Moon 1985 ) и меньший потребный объём кэша при заданной его эффективности. Многие сферы применения, встраиваемые системы в особенности, очень чувствительны к стоимости печатной платы и компонентов, так как они составляют изрядную часть затрат ( Ditzel et al. 1987b ).
Традиционным методом борьбы с увеличением размеров программ является использование иерархической структуры памяти, выстроенной в соответствии с параметром «объём-цена-время доступа». Структура может состоять из ( от большой-дешёвой-медленной к маленькой-дорогой-быстрой ): магнитной ленты, оптического диска, жёсткого диска, динамической памяти, внешней кэш-памяти и внутрипроцессорной кэш-памяти [* и регистров процессора ] . Поэтому правильным вариантом выражения «память дешева» является «медленная память дешева, а вот быстрая - чрезвычайно дорога».
Острота проблемы снижается в том случае, когда возможно оснастить процессор достаточным количеством памяти с приемлемым быстродействием и по сходной цене. Этого можно добиться, ограничивая максимальный размер программ объёмом самой быстрой памяти.
Обычно на самом верхнем уровне иерархии располагается кэш-память. Она работает по принципу многократного использования в течение небольшого времени небольших кусков программы. Таким образом, в первый момент использования инструкции она копируется из медленной памяти в кэш и остаётся там для дальнейшего использования. При повторном обращении к тому же участку программы и всех последующих время доступа к нему уменьшается. Ограниченный объём кэш-памяти приводит к тому, что любая инструкция, находящаяся в кэше, будет выброшена, если место потребуется для сохранения нового фрагмента. Проблемой является необходимость иметь кэш подходящего объёма для хранения участков программы достаточно длинных для повторного использования.
==119
Кэш-память, которая достаточна для хранения заданного числа инструкций, называемого «рабочим набором» , может существенно увеличить производительность системы. Как размер программы может повлиять на производительность? Предположим, что в рабочий набор входит некоторое число операторов языка высокого уровня, и рассмотрим эффект более компактной кодировки машинных инструкций. Интуитивно понятно, что если набор инструкций, который соответствует оператору языка высокого уровня, на «машине_A» кодируется компактнее, чем на «машине_B», то «машине_A» потребуется меньше кэш-памяти для хранения этих инструкций, чем «машине_B». В результате, «машине_A» потребуется меньше кэша для достижения того же среднего быстродействия памяти.
Davidson и Vaughan ( 1987 ) на примерах показали, что программы для RISC машин могут быть в 2.5 раза больше, чем они же, но для CISC архитектуры ( другие источники, в том числе производители RISC процессоров, говорят о коэффициенте 1.5 ). Они же показали, что для достижения той же производительности, что и у CISC, кэш-память для RISC машин должна быть в два раза больше. Более того, RISC машины с двойным кэшем по-прежнему получают в два раза больше кэш-промахов ( так как при заданном числе промахов на обращение имеем в два раза больше обращений к кэшу ). В результате для обеспечения такой же производительности им нужна более быстрая память. Данный факт подкрепляется эмпирическим правилом: RISC процессору с производительностью 10 MIPS нужно 128K байт кэш-памяти, а продвинутому CISC - не более 64K.
Размеры программ для стековых машин много меньше, чем для RISC или CISC компьютеров. Коэффициент сокращения объёма кода по сравнению с CISC вариантом при соблюдении некоторых ограничений, которые будут рассмотрены позднее, лежит в диапазоне от 2.5 до 8 раз ( Harris 1980 , Ohran 1984 , Schoellkopf 1980 ). Таким образом, в RISC компьютере один только кэш должен быть больше, чем весь объём программной памяти стекового процессора, чтобы иметь сравнимое время реакции подсистемы памяти! Складывающаяся ситуация напоминает анекдот: программистам на языке Си под Unix становится очень неуютно при объёме ОЗУ менее 8..16M и кеше в 128K байт, а программисты на FORTH всё ещё жарко спорят о том насколько на самом деле нужно стековым машинам адресное пространство выше 64K. [* Не будем забывать о сказанном стр. 48 - больших проектов на FORTH не существует ] .
Небольшие размеры программ не только уменьшают стоимость системы, но и увеличивают производительность, потому что растёт вероятность того, что нужная инструкция обнаружится в высокоскоростной памяти. Скорее всего, именно возможность размещения всей программы в быстрой памяти является ориентиром для её размеров.
==120
Из чего складываются столь скромные требования к памяти у стековых машин ? На размер программ влияют два фактора. Самый очевидный и чаще всего упоминаемый в литературе - небольшой размер машинных команд. Привычные архитектуры должны указывать в инструкции не только выполняемую операцию, но также операнды и режим адресации. Например, типичная инструкция регистровой машины, складывающая два числа, может выглядеть так:
ADD R1,R2
Инструкция должна сообщить не только код операции ( «ADD» ), но так же и то, что проводится она над двумя регистрами и что это регистры R1 и R2 .
Стековая инструкция должна указать только код операции «ADD», так как подразумевается, что операнды находятся на вершине стека. Операнды появляются только в операциях чтения памяти, записи в неё и сохранения непосредственного значения в стеке. WISC CPU/16 и Harris RTX 32P используют 8- и 9-битные поля операций соответственно, имея гораздо больше возможных кодов, чем на самом деле нужно для эффективного исполнения программ. Ограниченное кодирование инструкции процессоров, подобных Novix NC4016 , позволяют упаковывать две и более операции в одну директиву, лишь незначительно теряя в плотности кода по сравнению с байт-ориентированными машинами.
Не столь очевидной, но более важной причиной более компактных программ для стековых машин является эффективная поддержка кода с частым использованием процедур, называемого иногда «threaded code» ( Bell 1973 , Dewar 1975 ). Использование такого стиля программирования на обычных машинах возможно, но влечёт за собой значительный штраф по скорости исполнения. Фактически самым простым приёмом оптимизации для RISC и CISC машин является компиляция процедур как «подставляемого» кода. Вместе с обычным опытом программирования, гласящим, что слишком много вызовов подпрограмм ухудшают быстродействие, такая оптимизация ведёт к заметному увеличению размеров программ для обычных машин. [* Кроме того, встроенный код плохо кэшируется: последовательность инструкций та же, что и в соседней процедуре, но адреса другие и при обращении возникает кэш-промах. Проблему решает ассоциативный кэш, который учитывает не адреса, а содержимое, но он сложен, дорог и прожорлив. Собственно, inline код не будет кэшироваться вовсе, т.к. в общем случае не является повторно входимым. Об этом позаботился компилятор, размножая единственную процедуру на множество копий ] .
В противоположность иным архитектурам, стековые машины имеют эффективный механизм вызова подпрограмм. Накладные расходы на вызов минимальны, так как все рабочие параметры уже находятся в стеке и не требуют дополнительных циклов памяти для передачи. В большинстве стековых процессоров вызовы подпрограмм занимает один такт, а возврат из них в чаще всего не требует тактов вовсе, поскольку комбинируется с другими операциями.
Т.к. результаты исследований здесь не приводятся, утверждение о большей компактности кода стековых машин в сравнении с другими архитектурами требует некоторых пояснений. Размеры программ сильно зависят от используемого языка, компилятора, стиля программирования и набора инструкций целевого процессора. Кроме того, исследования, проводившиеся Harris, Ohran и Schoellkopf, относятся в большей степени к стековым машинам с переменной длиной инструкций, тогда как описанные в этой книге экземпляры имеют 16- и 32-разрядные директивы фиксированной длины. Фиксированная длина команд увеличивает объём кода, что отчасти компенсируется тем фактом, что процессоры, выполняющие язык FORTH непосредственно, будут иметь меньший размер программ [* в силу стековой природы языка ] . Это обстоятельство обусловлено активным употреблением вызовов подпрограмм, позволяющим повторное использование значительной части кода. И, наконец, из последующих разделов будет видно, что даже 32-разрядные модели, подобные RTX 32P , расходуют не так много программной памяти, как может показаться на первый взгляд.
==121
6.2.2 Сложность процессора и системы в целом
Обсуждая сложность компьютеров, следует различать два уровня: сложность процессора и сложность системы. Сложность процессора - это объём логики ( измеряемый площадью кристалла, числом транзисторов и т.п. ) в вычислительном ядре. Сложность системы учитывает процессор, встроенный в полностью функционирующее устройство, вспомогательные схемы, подсистему памяти и программное обеспечение.
CISC компьютеры с течением времени становятся всё тяжеловеснее. Их сложность вызывается необходимостью одновременного выполнения множества функций и в значительной степени усугубляется попыткой закодировать массу разнообразных инструкций с использованием большого числа форматов. Не добавляет простоты и поддержка многочисленных программных моделей и форматов данных. Любая машина, которой приходится обрабатывать упакованные десятичные данные для языка COBOL, выполнять матричные операции над числами с плавающей запятой на FORTRAN и обслуживать экспертную систему в LISP в вычислительной среде с разделением времени с приемлемой производительностью, не может не быть сложной !
Сложность CISC машин частично является результатом кодирования инструкций для сохранения относительно небольших размеров программ. Цель - уменьшить разрыв между семантикой [* смысловым наполнением ] языков высокого уровня и машинных диалектов и, тем самым, повысить эффективность кода. К сожалению, это приводит к ситуации, при которой почти вся площадь кристалла занята каналами передачи данных и сигналов управления ( например, модельные линейки 680x0 у фирмы Motorola и 80x86 у Intel ). Кроме того, сторонники RISC утверждают, что разработчикам CISC машин приходится платить не только площадью кристалла, но и производительностью.
Пределы, которых достигает сложность процессоров отдельных CISC машин, могут показаться чрезмерными, но их развитие подкрепляется понятным и хорошо обоснованным стремлением организовать простое и непротиворечивое взаимодействие между аппаратурой и программой. Правильность такого подхода демонстрирует модельный ряд компьютеров IBM System/370. Это семейство имеет единый набор ассемблерных команд и охватывает широкий диапазон возможностей и цен: от плат расширения для персональных машин, до суперкомпьютеров.
Простой и согласованный интерфейс между аппаратурой и программным обеспечением на уровне языка ассемблера позволяет использовать для нескольких моделей семейства один компилятор и, не слишком усложняя его конструкцию, выдавать неплохой код. Другое преимущество CISC процессоров - более компактные инструкции - уменьшают требования к объёму кэш-памяти, при сохранении приемлемой производительности. Таким образом, CISC архитектура стремится сократить сложность системы за счёт увеличения сложности процессора.
==122
В основе RISC машин лежит желание увеличить скорость процессора через его упрощение. Получающееся вычислительное ядро имеет меньше транзисторов, чем в CISC машинах. Цель достигается упрощением форматов инструкций и уменьшением их семантического [* смыслового ] наполнения. RISC процессоры делают немного работы, но и времени на неё тратят мало. Форматы инструкций выбираются из соображений соответствия выбранным языкам программирования и выполняемым задачам. Обычно это язык Си и целочисленная арифметика.
Сокращение сложности процессора даётся не бесплатно - большинство RISC машин имеют большие регистровые банки для хранения активно используемых данных. Регистровые банки должны располагаться в двухпортовой памяти ( позволяющей одновременный доступ по двум различным адресам ), чтобы можно было выбирать два операнда в каждом цикле. Более того, уменьшение семантического наполнения директив приводит к повышению требований к памяти для поддержания потока инструкций в процессор. Это означает, что для поддержания производительности приходится задействовать дополнительные внутрипроцессорные и общесистемные ресурсы. Кроме того, составной частью RISC архитектур является конвейер команд. Это приводит к необходимости дополнительной аппаратуры или усложнения конструкции компиляторов, учитывающих его наличие. Дополнительная аппаратура и специальные усилия требуются для корректности сохранения и восстановления состояния конвейера при отработке прерываний.
Наконец, различные стратегии реализации архитектур RISC предъявляют серьёзные требования к компиляторам, как-то: планирование использования конвейера для избежания столкновений, заполнение временнЫх промежутков при переходах и управление процессом загрузки и выгрузки содержимого регистровых банков. Упрощение архитектуры процессора облегчает доводку кристалла, но в то же время компилятор заметно усложняется, затрудняя и удорожая разработку и отладку [* программ ] .
Упрощение RISC процессоров ведёт к отложенному ( и, возможно, более значительному ) увеличению сложности системы.
Стековые машины претендуют на достижение баланса между сложностью вычислительного ядра и системы в целом. Конструкции стековых процессоров упрощаются не за счёт сокращения числа инструкций, а за счёт уменьшения числа источников данных, с которыми могут работать инструкции: все действия проводятся над верхними элементами стека. С этой точки зрения стековые машины можно назвать компьютерами с сокращённым числом операндов ( ROSC ), в противоположность компьютерам с сокращённой системой команд ( RISC ).
Сокращение возможностей выбора операндов вместо сокращения объёма выполняемой с помощью инструкции работы имеет несколько преимуществ. Директивы могут быть очень компактными, так как им нужно указывать только операцию и не надо уточнять расположение источников. Внутрипроцессорная стековая память может быть однопортовой, так как в каждом такте сохраняется или удаляется только один элемент стека ( предполагается, что два верхних элемента хранятся в регистрах ). Ещё важнее то, что известное заранее местоположение операндов [* и возможность получения немедленного доступа ] делает ненужным конвейер для их предвыборки. Все операнды доступны немедленно через вершину стека. Примером могут служить два регистра T и N кристалла NC4016 , в то время как в RISC машинах регистры со случайным доступом исчисляются десятками, если не сотнями.
==123
Подразумеваемое поле операндов упрощает машинные команды и сокращает их разнообразие. В результате, у стековых компьютеров, в отличие от RISC машин [* не говоря уж о CISC ] , число форматов инструкций ограничивается единицами. А чем их меньше, тем проще декодирующая логика и выше скорость работы.
Стековые компьютеры весьма незатейливы: вычислительное ядро 16-разрядного процессора обычно занимает 20..35 тысяч транзисторов. Сравните эту цифру с [* 134 тысячами у 80286, ] 275 тысячами у кристалла 80386 фирмы Intel и 200 тысячами у 68020 фирмы Motorola. Даже с учётом того, что оба они 32-разрядные, разница значительная.
Сбалансированные по формату и числу операндов инструкции стековых машин позволяют упростить транслятор. Большинство компиляторов для регистровых процессоров в ходе вычисления выражений фактически переходят к «стековому» взгляду на программу и отображению стека на набор регистров. [* Ситуация изменилась только с появлением LLVM ] . А инструментам для стековых машин приходится делать гораздо меньше работы при переводе исходного текста в язык ассемблера. [* А если он за FORTH берётся /то просто тратит меньше сил ] . Скажем, непревзойдённой простотой и универсальностью хорошо известны компиляторы FORTH [* ещё и язык стековый ] .
Невелика и сложность стековых вычислительных систем в целом. Небольшие размеры программ позволяют разместить их в микросхемах быстрой памяти целиком, делая ненужным использование экзотических схем кэширования для получения хорошей производительности.
В тех случаях, когда программа и/или данные слишком велики, для их размещения можно использовать управляемую программно иерархию: фрагменты, используемые часто, можно поместить в быструю память, а код, используемый редко, - в медленную. Быстрые однотактные обращения к подпрограммам в скоростном сегменте делают такой подход очень эффективным.
В большинстве случаев, например, при передаче параметров стек данных работает в качестве кэша, и при необходимости его элементы могут перемещаться в быструю память и из неё под управлением программы. Несмотря на то, что обычный кэш данных и, в меньшей степени, кэш команд могут обеспечить некоторый прирост производительности, он часто не только не нужен, но и нежелателен для большинства малых и средних аппаратных решений. [* Сложнее, дороже, ниже надёжность ] .
Таким образом, ограничивая число операндов, стековые машины снижают сложность процессора. Этот способ не приводит ни к уменьшению числа инструкций, ни к взрывному увеличению объёма вспомогательного аппаратного и программного обеспечения, требуемых для работы процессора. Результатом снижения сложности является увеличение площади кристалла, доступной для программной памяти или специализированных модулей. В качестве интересного варианта использования таких свойств можно попробовать уместить всю программную память внутри кристалла, сделав её более быстрой, чем внешний кэш. Тогда исчезнет необходимость использования сложных схем организации памяти, а быстродействие останется высоким.
==124
6.2.3 Производительность процессора
Производительность процессора очень неудобная для обсуждения тема. Невероятное количество усилий было потрачено в спорах о том, какой процессор лучше. Часто такие обсуждения базируются на беглом знакомстве с сомнительными результатами измерения производительности и подогреты собственной заинтересованностью, пристрастиями или стремлением получить скидку при закупках.
Одна из причин сложности сравнения вытекает из неопределённости области использования. Результаты тестирования производительности при целочисленных вычислениях ничего не скажут о скорости обработки чисел с плавающей запятой, работе в деловых приложениях или выполнении символьных операций. Наверно, самое большее, на что можно рассчитывать, используя результаты тестов, это выяснить, что «процессор_A» лучше, чем «процессор_B» при работе в заданном окружении ( включая кэш-память, диски, тактовую частоту и т.п. ), с заданной операционной системой, при использовании заданного компилятора и языка программирования, но только в процессе исполнения данных конкретных тестов. Понятно, что сравнение производительности разных машин - тема непростая.
Измерение производительности принципиально разных архитектур ещё сложнее. Основные трудности представляет определение объёма работы, выполняемой одной инструкцией. Разница между командой вычисления полинома в архитектуре VAX и директивой передачи данных между регистрами у RISC машины делает саму идею «числа операций в секунду» в лучшем случае бесполезной ( даже если результаты измерений нормализуются с использованием тех самых сомнительных методик определения производительности ). Проблем добавляют и различные технологии производства процессоров ( биполярная, ЭСЛ, n-МОП, КМОП и др. ), уровни проектирования ( заказная разработка, технология стандартных ячеек или вентильные матрицы ). Кроме того, каждая методика измерений требует учёта влияния эффектов от разницы фабричных техпроцессов [* слишком глубоко копает ] . Более того, производительность очень зависит от параметров используемого программного обеспечения. Проблема состоит в том, что в жизни быстродействие конкретного компьютера зависит не только от тактовой частоты процессора, но и от эффективности аппаратного окружения, операционной системы, языка программирования и компилятора.
Список трудностей должен подвести читателя к мысли, что здесь решения проблемы измерения производительности он не получит. Вместо этого [* следите за руками ] будут обсуждаться причины, по которым стековые машины можно сделать более быстрыми, чем другие архитектуры [* скачок мысли, что и говорить, сногсшибательный ] при выполнении последовательности инструкций. Кроме того, будут рассмотрены источники хороших скоростных характеристик стековых систем и наиболее подходящий для них тип программ.
6.2.3.1 Скорость исполнения инструкций
==125
Наиболее сложные RISC процессоры гордятся наивысшей возможной скоростью работы - одна инструкция за один период тактового сигнала ( цикл ). Такой результат достигается за счёт конвейерной обработки команд. Работа разбивается на выдачу адреса инструкции, выборку инструкции, декодирование инструкции, выборку данных, исполнение инструкции и сохранение результата, как показано на рис. 6.1a . Такое разбиение процесса выполнения увеличивает общую скорость, но порождает некоторые проблемы. Самой важной, из которых, является управление зависимостями данных. Проблема возникает, когда одна инструкция зависит от результата выполнения предыдущей и вынуждена ожидать, покуда первая сохранит свои результаты, перед тем, как выбрать их в качестве своих операндов. Существует несколько аппаратных и программных стратегий борьбы с потерями от зависимостей, но ни одна из них не решает проблему полностью.
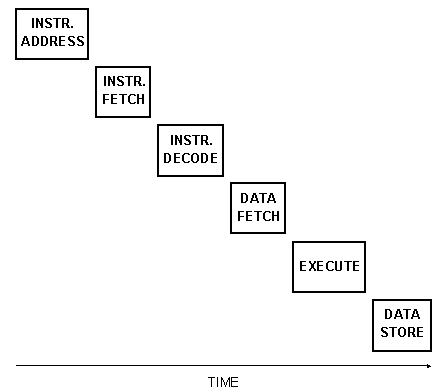
Рис. 6.1a Перекрытие фаз исполнения инструкций - непосредственное исполнение
Стековые машины могут исполнять программу [* речь здесь идёт о потоке инструкций ] столь же быстро, как RISC машины, возможно, даже быстрее и без проблем с зависимостями данных [* на самом деле зависимость есть и стопроцентная ] . Часто можно услышать, что регистровые машины эффективнее стековых, потому что в них можно организовать конвейер, а в стековых - нет. Конвейер невозможен, так как каждая последующая инструкция зависит от эффектов воздействия на стек предыдущей . Но самое главное, стековые машины не нуждаются в конвейере для того, чтобы работать столь же быстро, как RISC машины. [* Ага, щас! Нуждаются, конечно, но в более коротком ] .
[* Это я выделил. Данная фраза, возможно, главная мысль книги и приговор стековым суперкомпьютерам. Принципиальная зависимость всех стековых инструкций друг от друга не позволяет распараллеливать их работу, ни в каком виде. Их можно выполнять только одну за другой, и никак иначе. Finita ].
==126
Рассмотрим, как меняется последовательность выполнения при переходе от RISC к стековой машине. Обоим процессорам необходимо производить выборку инструкции, и у обоих эта операция может проводиться одновременно с выполнением предыдущей машинной команды. Для удобства мы можем объединить этот этап с декодированием для RISC и большая часть стековых машин. Этапа декодирования нет в RTX 32P и ему подобных процессорах, которым не требуются разбираться с форматом команды и заниматься сравнительным разбором отдельных полей, и они, соответственно, конструктивно проще, чем RISC машины. [* Операции сравнения не нужны, но зато в случае RTX 32P приходится проводить две выборки из памяти. Одна - чтение собственно инструкции из программной памяти, как и у всех прочих, вторая - чтение соответствующей микроинструкции из микропрограммной памяти вместо разбора и сравнения полей. А обращение к памяти обходится дороже, чем сравнение ] .
На следующем шаге выполнения основные отличия становятся заметнее. RISC процессоры должны потратить его на обращение к операндам, которые станут известны после завершения этапа декодирования ( как минимум частичного ). В качестве источника данных для АЛУ RISC инструкция определяет два и более регистра. Стековой машине не надо получать доступ к операндам - они ожидают использования на вершине стека. В результате исключается этап подготовки операндов. Кроме того, доступ к стеку может быть быстрее, чем доступ к регистрам, так как однопортовую стековую память можно сделать более компактной и, соответственно, более скоростной, чем двухпортовую регистровую память. [* Речь, по-видимому, идёт о регистровом файле ] .
==127
Этап выполнения операции и в RISC, и в стековой машине будет одинаковым, так как обе используют ту или иную форму АЛУ. Но даже здесь стековые машины могут иметь преимущество в виде вычисления функций над верхними элементами стека до завершения этапа декодирования инструкции, как это сделано в модели M17 .
Фаза сохранения результата занимает в RISC машинах отдельный шаг, так как результат должен быть помещён в регистровый файл. Операция записи конфликтует с операцией выборки очередной инструкции, требуя либо введения задержки, либо использования для регистрового файла трёхпортовой памяти. Данное действие может потребовать сохранения выхода АЛУ во временном регистре, содержимое которого будет помещено в регистровый файл в следующем такте. [* Либо очень разветвлённых путей передачи данных, когда операндами АЛУ могут служить любые элементы регистрового файла. Яркий пример - RISC процессор MSP430 ] . В противоположность таким сложностям, стековой машине достаточно записать выход АЛУ в регистр верхнего элемента стека. В RISC машинах появляется необходимость в механизме передачи результата, чтобы исключить такты ожидания, если результат нужен уже в следующей инструкции. В стековых машинах выход АЛУ всегда доступен в качестве входного операнда.
==128
Рис. 6.1b показывает, что для обеспечения той же пропускной способности RISC машинам требуется не менее трёх шагов конвейера инструкций, плюс, возможно, четвёртый: выборка инструкции, выборка операндов, вычисление и сохранение. Кроме того, как уже было отмечено, RISC подход имеет несколько принципиальных проблем с зависимостями данных и ресурсными конфликтами, которых нет у стековых машин. Рис. 6.1c показывает два шага конвейера, нужные стековым машинам: выборка инструкции и исполнение.
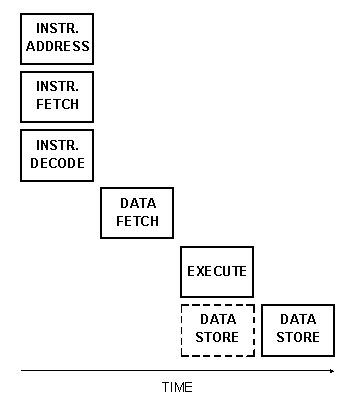
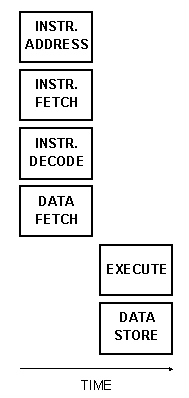
Рис. 6.1b Перекрытие фаз исполнения инструкций - типичная RISC машина
Рис. 6.1c Перекрытие фаз исполнения инструкций - типичная стековая машина
Всё это означает, что нет причин, по которым стековые машины должны быть хоть сколь-нибудь медленнее, чем RISC компьютеры, в части исполнения инструкций, и есть основания полагать, что при одинаковых технологиях производства кристаллов, стековые процессоры будут проще и быстрее.
6.2.3.2 Производительность системы
Измерение производительности системы ещё сложнее, чем измерение производительности процессора. Производительность системы включает не только число исполняемых за единицу времени последовательно расположенных машинных команд, но и скорость обработки прерываний, переключения контекста и ухудшение параметров под влиянием условных переходов и вызовов подпрограмм. Комплексные подходы, подобные технике трёхмерного измерения производительности ( Rabbat et al. 1988 ), дают более точные результаты, чем простой замер скорости выполнения инструкций.
Разработчики RISC и CISC машин ориентируются на исполнение линейного кода как основного режима работы. Частые вызовы подпрограмм могут существенно ухудшить производительность таких архитектур. В цену вызова функции входят не только затраты на сохранение счётчика программы и выбора нового потока инструкций, но, вдобавок, сохранения и восстановления регистров и конвейера команд, а также реорганизации данных. Само существование отдельного стека адресов возврата показывает, сколь много внимания в стековых машинах уделяется управляющим структурам программы, типа вызовов процедур. Все рабочие переменные таких машин хранятся в аппаратном стеке и время, нужное для подготовки параметров для подпрограммы обычно ограничивается скоростью исполнения единственной инструкции «DUP» или «OVER».
Условные переходы затрудняют работу обычных процессоров. Причиной являются схемы предвыборки инструкций и конвейеры, рассчитанные на последовательное исполнение программы. Условные переходы вызывают задержку их работы до момента выяснения направления перехода. Единственной альтернативой является принудительное продолжение предвыборки по одной из ветвей в надежде, что эта работа не будет делаться впустую. RISC машины решают проблему условных переходов использованием «времени ожидания перехода» ( «branch delay slot» ) ( McFarling & Hennesy 1986 ) и размещением после перехода неконфликтных инструкций или пустых операций.
[* Branch Delay Slots are one of the awkward features of RISC architectures. RISC CPUs are pipelined by definition, so while the current instruction is in execution, the following instruction(s) will be in the pipeline already. If there is for example a conditional branch in the instruction stream, the CPU cannot know whether the next instruction is the one following the branch or the instruction at the target location until it has evaluated the branch. This would cause a bubble in the pipeline; therefore some RISC architectures have a branch delay slot: The instruction after the branch will always be executed, no matter whether the branch is taken or not.
So in practice, you can put the instruction that would be before the branch right after the branch, if this instruction is independent of the branch instruction, i.e. doesn’t access the same registers. Otherwise, you can fill it with a NOP. Out-of-order architectures can do this reordering at runtime, so there would be no need for a delay slot. Nevertheless, the delay slot is a feature of the architecture, not the implementation ].
[* Конвейер команд является конструктивной особенностью RISC процессоров. Это значит, что, когда выполняется одна инструкция, следующая ( /следующие ) за ней уже заняла своё место в очереди. Если в потоке исполнения встретился условный переход, процессор не может понять, относится ли следующая команда в очереди к истинной или к ложной ветви выбора, пока не просчитает условие. Данная ситуация создаёт в потоке исполнения «пробку». Для борьбы с данным явлением некоторые RISC архитектуры вводят «branch delay slot»: инструкция сразу после команды условного перехода исполняется всегда, независимо от истинности или ложности заданного условия.
Таким образом, инструкция, которая предшествовала условному переходу, может быть помещена сразу после него, если её результат не влияет на условие перехода. В противном случае сразу после перехода ставят «NOP» . Архитектуры, допускающие изменение порядка следования инструкций «на лету» проделывают описанный фокус самостоятельно и в специальной задержке не нуждаются. Так или иначе, но «задержка ожидания перехода» является свойством архитектуры, а не её конкретного воплощения ].
Стековые машины обрабатывают переходы иначе, но в любом случае они выполняются за один такт и не требуют дополнительного времени ожидания или усложнения компилятора. NC4016 и RTX 2000 решают проблему использованием памяти со скоростью обращения большей, чем тактовая частота процессора. Это приводит к появлению времени на вычисление адреса перехода и выборки следующей инструкции в установленное время в конце цикла. Такое решение работает, но по мере роста тактовой частоты процессоров появляются проблемы с быстродействием памяти программ [* т.е. решение плохое, так как предоставляет почётное право решения проблемы следующему поколению инженеров ] .
==129
FRISC 3 вычисляет условия перехода отдельной инструкцией, после чего другой инструкцией выполняет сам переход. Это очень разумный подход, так как перед практически любым ветвлением на любой машине требуется проводить сравнение или ещё какие-либо операции. Вместо простого сравнения ( обычно элементарного вычитания ) FRISC 3 указывает, какое именно условие будет использоваться при переходе, сводя все вычисления в директиве перехода к простой проверке одного бита. [* Можно использовать «теневой» TOS для стека возврата: TOS и его теневая копия заполняются адресами двух ветвей программы одновременно, а окончательный выбор делается по результатам сравнения. Тот регистр, который выбран, становится TOS , а другой теневой копией ] .
RTX 32P использует микрокод для создания комбинации сравнения и перехода, которая исполняется за удвоенное время обычной инструкции, то есть за время пары сравнение-переход. Например, сочетание «= 0BRANCH» можно закодировать одной четырёхтактовой инструкцией ( время двух обычных инструкций ).
Обработка прерываний в стековых машинах выполняется много проще, чем в RISC или CISC архитектурах. В CISC процессорах сложные многотактовые инструкции могут выполняться столь долго, что придётся делать их прерываемыми, что повлечёт за собой большой объём дополнительной логики управления и значительные издержки при сохранении и восстановлении состояния процессора в середине инструкции. Положение RISC машин немногим лучше, так как при каждом прерывании им приходится сохранять и восстанавливать состояние конвейера [* т.е. RISC можно уподобить CISC машине, у которой все инструкции ( читай, «состояние конвейера» ) длинные и должны быть прерываемыми ] . И, кроме того, и в RISC, и в CISC компьютерах есть регистры, требующие сохранения и восстановления для того, чтобы предоставить обработчику прерывания ресурсы для выполнения работы. Для обеих архитектур нормально тратить несколько микросекунд при реакции на прерывание.
Стековые же машины тратят на переход к обработчику всего несколько тактов. Они рассматривают прерывания как подпрограммы, вызываемые аппаратно. Конвейера команд, требующего сохранения, нет и единственное, что надо сделать - вставить в поток инструкций адрес обработчика в форме вызова подпрограммы и сохранить в стеке состояние маски прерываний перед запрещением текущего ( чтобы не впасть в бесконечную рекурсию при реакции на прерывание ). После передачи управления обработчику нет нужды сохранять какие-либо регистры, так как новая подпрограмма может просто положить данные на вершину стека. Чтобы дать представление о скорости реакции на прерывание, сообщим, что RTX 2000 тратит всего четыре такта ( 400 ns ) между моментом появления запроса на обслуживание и началом выполнения первой инструкции обработчика.
Создаётся впечатление, что стековые машины будут тратить больше времени, чем другие архитектуры, на переключение контекста. Представленные ниже результаты экспериментов показывают, что это не так.
Последним преимуществом стековых машин, вытекающим из простоты их аппаратной реализации, является наличие дополнительного места для специализированных модулей в заказных версиях процессора. Например, RTX 2000 фирмы Harris имеет аппаратный умножитель. Другими примерами дополнительной аппаратуры могут служить модули быстрых преобразований Фурье, АЦП и ЦАПы и порты последовательной связи. Подобные опции могут существенно сократить число компонентов в вычислительной системе и кардинально повысить скорость исполнения программы.
==130
6.2.3.3 Наиболее подходящие для стековых машин типы программ
Типы задач, которые стековые компьютеры обрабатывают очень хорошо, включают: программы с большим количеством вызовов процедур, программы с большим количеством управляющих структур, программы для символьных вычислений ( часто требующих интенсивного использования стека и рекурсии ), обработка часто возникающих прерываний и программы, рассчитанные на небольшой объём памяти.
6.2.4 Однородность процесса выполнения программ
Сложные RISC и CISC машины используют множество специальных приёмов, которые позволяют иметь высокую среднестатистическую производительность на больших временнЫх интервалах, но не гарантируют её на малых. В число таких приёмов входят очереди предвыборки инструкций, сложные конвейеры, изменение последовательности выполнения инструкций, кэш-память, буфера адресов назначения при ветвлении и схемы предсказания ветвлений. Проблема в том, что все перечисленные методы не могут гарантировать увеличения мгновенной производительности в какой-либо конкретный момент времени. Неудачное сочетание внешних событий или значений данных могут приводить к множественным промахам кэш-памяти, сбросам очередей и прочим задержкам. Высокая среднестатистическая производительность приемлема для некоторых видов программ, но для задач реального времени требуется предсказуемая мгновенная производительность.
В стековых машинах все перечисленные приёмы не используются. Результатом отсутствия сложных механизмов исполнения кода является высокая однородность производительности при любом временном масштабе. [* Т.е. линейная зависимость от частоты - в высшей степени ценное свойство ] . Как будет видно из Части _8 , это одно из основных требований к приложениям реального времени.
==130
