
5.3 Архитектура RTX 32P
==97
5.3.1 Введение
RTX 32P фирмы Harris Semiconductor - 32-разрядный представитель семейства «Real Time Express». Это прототип для линейки коммерческих 32-разрядных стековых процессоров.
RTX 32P - КМОП вариант модели CPU/32 фирмы WISC Technologies ( Koopman 1987c ), который был собран на дискретных TTL компонентах. В свою очередь CPU/32 вырос из WISC CPU/16 , описанного в §4.2 . Такая предыстория определила конструкцию - RTX 32P микрокодовая машина с внутрипроцессорной оперативной памятью микрокода и внутрипроцессорными же стеками.
RTX 32P реализован в виде набора из двух микросхем и задумывался как универсальный стенд для отладки архитектуры. Он включает очень большие внутрипроцессорные стеки данных и возврата и много памяти микрокода. Столь заметный объём быстрой оперативной памяти вынуждает использовать две микросхемы, но такое решение не противоречит исходной цели - созданию отладочной исследовательской платформы. Основное назначение RTX 32P - задачи управления в реальном масштабе времени.
==98
Базовым языком программирования RTX 32P является FORTH. Коммерческий преемник будет модифицирован в направлении увеличения поддержки обычных языков, таких как Си, Ada и Pascal, языков специального назначения, типа LISP и Prolog, и функциональных языков.
Любая команда RTX 32P длится два такта ( или более ), в каждом из которых исполняется отдельная микроинструкция, т.е. выполняется два цикла работы АЛУ на каждое обращение к внешней памяти, включая выборку самого кода операции. Доводы в пользу подобной концепции подробнее обсуждаются в §9.4 .
5.3.2 Блок-схема
Блок-схема RTX 32P приведена на рис. 5.3 .
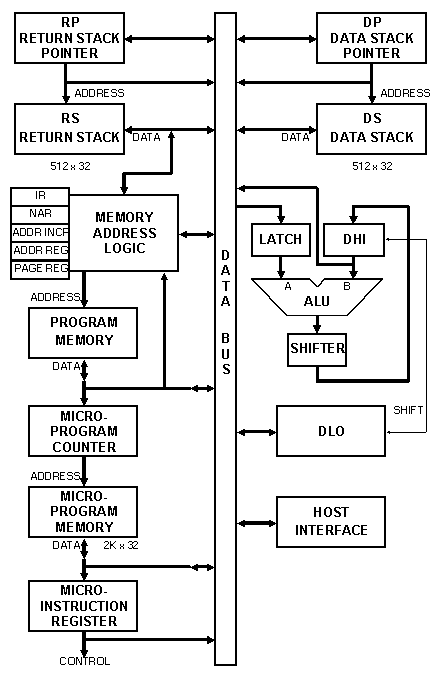
Рис. 5.3 Блок-схема RTX 32P
Стеки данных и возврата реализованы одинаково и состоят из 9-разрядных реверсивных счётчиков - указателей стека ( Stack Pointer ) и памяти объёмом 512 32-разрядных слов. Указатели доступны системе для чтения и записи, обеспечивая, тем самым, простой способ доступа к данным в глубине стека.
Секция ALU состоит из обычного многофункционального арифметическо-логического устройства с регистром DHI для хранения промежуточных результатов. По традиции DHI является буфером верхнего элемента стека. Это означает, что аппаратный указатель стека данных адресует элемент, видимый программисту как второй сверху. В результате операции над двумя элементами, такие как сложение, могут выполняться за один такт, при этом сторона «B» АЛУ считывает второй элемент из стека данных, а сторона «A» - верхний элемент стека из регистра DHI .
Защёлка на входе «B» АЛУ прозрачна в нормальном состоянии и используется для хранения данных в течение одного цикла тактирования. Такая схема ускоряет операции обмена данными между DHI и стеком данных [* вернее, даёт больше времени на такой обмен ] .
В машине нет кодов условий, доступных на уровне машинного языка. Сложение с переносом и другие операции повышенной точности поддерживаются микрокодом, который помещает флаг переноса в стек в виде логического значения ( «0» для сброшенного флага и «-1» для установленного ).
Регистр DLO сохраняет промежуточные результаты на время исполнения одной инструкции. DHI и DLO являются сдвиговыми регистрами и позволяют сдвигать 64-разрядные числа при умножении и делении.
Внешний интерфейс ( Host Interface ) используется для связи с управляющим персональным компьютером. Все запоминающие устройства внутри кристалла построены только по технологии оперативной памяти и поэтому внешний компьютер необходим для инициализации процессора.
В RTX 32P нет счётчика программы . [* Так тоже можно ! ] Каждая инструкция содержит адрес следующей или обращается к верхнему элементу стека адресов возврата. Такое решение было принято с учётом того, что программы на языке FORTH содержат очень много вызовов функций. В §6.3.3 особенности формата инструкций RTX 32P обсуждаются подробнее.
==99
==100
Вместо счётчика программы в блок адресной логики ( MAL ) включён «регистр очередного адреса» ( NAR ), хранящий адрес очередной инструкции. Для обращения к оперативной памяти используется регистр адреса ( ADDR REG ). Блок также содержит схему «увеличения-на-4» [* в байтах ] для формирования адреса возврата при вызове подпрограммы. Стек возврата и блок адресной логики могут быть отключены от системной шины данных ( Data Bus ), поэтому вызовы процедур, возвраты из них и безусловные переходы могут выполняться одновременно с другими операциями, что приводит в большинстве случаев к нулевым затратам времени на передачу управления.
Системная память общим объёмом до 4Гб адресуется побайтно. Инструкции и 32-битные данные должны быть выровнены по границе 32-разрядного слова. Имеющиеся образцы RTX 32P из-за ограниченного количества выводов корпуса могут работать только с 8Мб памяти.
Микропрограммная память находится внутри процессора, организована как массив из 2К 30-разрядных элементов и адресуется как 256 страниц по 8 слов каждая. Для каждого кода команды отводится отдельная страница на 8 слов. Счётчик микропрограммы ( Microprogram Counter ) формирует 9 разрядов адреса страницы, из которых в данной реализации используются 8 младших. 3 оставшихся бита задают адрес следующей микроинструкции внутри страницы. Самый младший из них является результатом вычисления одного из восьми возможных условий [* а два других прямо задаются в коде микроинструкции ] . Такая схема позволяет организовывать переходы и циклы в ходе выполнения одного кода операции.
«Декодирование» инструкции выполняется простой загрузкой в счётчик микропрограммы 9-битного кода операции, который является адресом страницы в микропрограммной памяти ( Microprogram Memory ). Счётчик позволяет при необходимости объединять в процессе исполнения несколько страниц микрокода.
Регистр микроинструкций ( MIR ) хранит выходные данные микропрограммной памяти. Это позволяет выбирать следующую микрокоманду параллельно с исполнением текущей. MIR полностью устраняет время доступа к микропрограммной памяти с основного пути распространения сигналов системы и одновременно вводит минимальное время исполнения инструкции в два такта. Если инструкция может быть выполнена за один такт, то для правильного прохождения через схему выборки к ней добавляется пустая микрооперация.
Интерфейс с управляющей машиной ( Host Interface ) позволяет RTX 32P работать в двух режимах: основном и подчинённом . В подчинённом режиме RTX 32P управляется с персонального компьютера. Подчинённый режим позволяет загружать программу и микропрограмму, изменять содержимое любого регистра и ячейки памяти для инициализации системы или отладки. В основном режиме RTX 32P занят исполнением программы, а управляющий компьютер наблюдает за регистром состояния, ожидая запроса на обслуживание. Пока RTX 32P находится в основном режиме, управляющий компьютер может ожидать в сервисном цикле или выполнять другие задачи, занимаясь, например, считыванием данных с диска или выводом изображений и время от времени проверяя регистр состояния. RTX 32P может ожидать обслуживания со стороны управляющей машины сколь угодно долго.
==101
5.3.3 Обзор системы команд
В RTX 32P есть только один показанный на рис. 5.4 формат инструкции. Он включает 9-разрядный код операции, т.е. номер страницы микропрограммной памяти и 2-разрядное поле управления ходом программы, где можно выбрать переход, вызов подпрограммы или возврат из неё. Для вызова подпрограммы или перехода позиции 2..22 инструкции содержат старшие биты 23-разрядного целевого адреса, выровненного по границе слова [* два младших бита равны нулю ] . Специальные команды дальних переходов и вызовов выполняются с использованием регистра страницы в модуле MAL, что ограничивает размер программ 8M байт. Операции выборки и сохранения данных работают с полным адресным пространством в 4Гб.
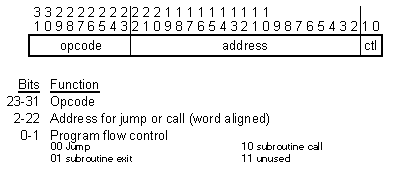
Рис. 5.4 Формат инструкций RTX 32P
Везде, где это возможно, компилятор для RTX 32P объединяет код операции и следующий за ним вызов подпрограммы, возврат управления или переход, в одну машинную инструкцию. В тех случаях, когда такое сокращение невозможно, вместе с командами передачи управления пакуется пустая операция ( «NOP» ) либо вместе с операцией компонуется переход на следующую по порядку инструкцию [* не забываем, что в процессоре нет счётчика команд и в каждой машинной инструкции должен содержаться адрес очередной директивы ] . Концевая рекурсия - пара последовательных инструкций «вызов подпрограммы, возврат управления» - заменяется единственной командой перехода в начало вызываемой подпрограммы, позволяя экономить на одной команде возврата управления, которую в противном случае пришлось бы исполнять дважды ( и в вызываемой, и в вызывающей процедуре ).
Так как микрокод в RTX 32P хранится в оперативной памяти, пользователь может его менять. Стандартная программная среда для RTX 32P ( CPU/32 ) - MVP-FORTH - диалект языка FORTH-79 ( Haydon 1983 ). Некоторые из слов FORTH, включённые в базовый набор микрокодовых инструкций, показаны в табл. 5.2a , 5.2b , 5.2c , 5.2d и 5.2e . Примечательны их число и сложность.
==102
Таблица 5.2(a) Система команд RTX 32P - примитивы FORTH ( см. Приложение _B , табл. B.1 )
| ! | 2* | AND | DUP | OVER |
| + | 2/ | BRANCH | I | R> |
| +! | < | D! | I' | R@ |
| - | PICK | D+ | J | ROT |
| 0 | ROLL | D@ | LEAVE | S->D |
| 0< | = | DDROP | LIT | SWAP |
| 0= | >R | DDUP | NEGATE | U* |
| 0BRANCH | ?DUP | DNEGATE | NOP | U/MOD |
| 1+ | @ | DROP | NOT | XOR |
| 1- | ABS | DSWAP | OR |
Таблица 5.2(b) Система команд RTX 32P - Составные примитивы FORTH
| <variable> @ прочитать переменную | LIT + | SWAP ! |
| <variable> @ + прочитать и прибавить переменную | OVER + | SWAP - |
| <variable> ! сохранить переменную | OVER - | SWAP DROP |
| @ + | R> DROP | |
| DUP @ | R> SWAP >R |
Набор команд RTX 32P может быть расширен или изменён пользователем.
==103
Таблица 5.2(c) Система команд RTX 32P - Специальные слова
Ниже приведены операции языка FORTH с дополнительной микрокодовой поддержкой.
Таблица 5.2(d) Система команд RTX 32P - Слова для поддержки высокоуровневых операций
| SP@ | считывает содержимое указателя стека | |
| SP! | инициализирует указатель стека | |
| RP@ | считывает содержимое указателя стека возврата | |
| RP! | инициализирует указатель стека возврата | |
| MATCH | примитив сравнения строк | |
| ABORT" | слово проверки и информирования об ошибке | |
| +LOOP | цикл увеличения переменной | |
| /LOOP | цикл беззнакового увеличения переменной | |
| CMOVE | перемещение строки | |
| < CMOVE | перемещение строки в обратном порядке | |
| DO | инициализация цикла | |
| ENCLOSE | примитив для разбора текста | |
| LOOP | цикл увеличения на 1 | |
| FILL | слово для инициализации блока памяти | |
| TOGGLE | примитив для установки/сброса отдельных битов |
Таблица 5.2(e) Система команд RTX 32P - Расширенные математические операции и действия над числами с плавающей запятой
Примечание:
CIN и COUT - логические флаги в стеке.
- CIN
- исходное состояние переноса,
- COUT
- итоговое состояние переноса.
RTX 32P хранит микрокод в оперативной памяти, что позволяет пользователю добавлять или изменять любую требуемую инструкцию. Приведённый список просто указывает состав стандартной поставки программного обеспечения.
==104
Табл. 5.2b показывает некоторые общеупотребительные комбинации слов FORTH, доступные в виде одной инструкции. В табл. 5.2c представлены слова, используемые в низкоуровневых операциях FORTH, подобных вызову и возврату из подпрограмм. Табл. 5.2d содержит высокоуровневые слова FORTH, поддерживаемые специализированным микрокодом напрямую. В табл. 5.2e перечислены слова для вычислений с повышенной точностью и 32-разрядные вычисления с плавающей запятой.
Так как сложность инструкций меняется весьма значительно, столь же значительно меняется и время их исполнения. Простые слова, такие как «+» и «SWAP», занимают 2 микротакта ( один цикл обращения к памяти ) каждая. Сложные, подобные «Q+» ( 128-разрядное сложение ), могут потребовать 10 и более микроинструкций, но по-прежнему исполняются гораздо быстрее, чем соответствующий код высокого уровня. При необходимости, можно написать на микрокоде цикл, который будет длиться тысячи тактов, занимаясь, к примеру, перемещением блока данных.
==105
Как уже говорилось ранее, каждая инструкция обращается к странице микропрограммной памяти, соответствующей 9-разрядному коду операции и вызывает последовательность микроинструкций, единый формат которых показан на рис. 5.5 . Используется горизонтальный способ кодирования, разделяющий микродирективу на несколько полей, каждое из которых отвечает за свою часть аппаратуры.

Рис. 5.5 Формат микроинструкции RTX 32P
Как и в случае WISC CPU/16 , простота стековой архитектуры и конструкции RTX 32P тянут за собой простоту формата микрокода. В данном случае он требует всего 30 бит и подобен формату упомянутого CPU/16.
Биты 0..3 микроинструкции указывают источник данных на системной шине данных . Две комбинации битов используются для перевода RTX 32P в режимы последовательного умножения и деления 32- или 64-разрядных чисел.
Биты 4..7 выбирают приёмник на шине данных. Есть два особых случая: DHI всегда загружается с выхода АЛУ, а с помощью битов 22..23 в качестве дополнительного приёмника может быть выбран DLO . Биты 8..9 и 10..11 управляют указателями стека данных и возврата соответственно. Биты 12..13 контролируют сдвиг выхода АЛУ. Возможен сдвиг на один разряд вправо или влево и 8-разрядный сдвиг вправо.
Разряды 14..15 не используются и физически отсутствуют в массиве памяти микрокода. Биты 16..20 задают режим работы АЛУ. Бит_21 управляет состоянием входного бита переноса. При синтезе арифметических операций повышенной точности микрокод выполняет переходы в зависимости от наличия или отсутствия переноса из нижней половины результата, после чего устанавливает нужное значение бита_21 . Биты 22..23 отвечают за загрузку и сдвиг регистра DLO .
Биты 24..29 используются для вычисления 3-разрядного смещения внутри страницы при выборе следующей микроинструкции. Биты 24..26 задают один из восьми кодов условий, который сформирует младший разряд смещения, а биты 27..28 прямо задают два следующих разряда. Это позволяет выполнять переходы и ветвления кода в пределах одной страницы в каждом такте. Бит_29 указывает на необходимость увеличения 9-разрядного счётчика микропрограммы , что позволяет микрокоду занимать более одной страницы. Бит_30 инициирует декодирование следующей инструкции. Он необходим, потому что время исполнения инструкций различается [* то есть архитектура требует от программиста не только прямо указать адрес следующей инструкции, но и момент окончания исполнения текущей. Объектно-ориентированное программирование наоборот - увеличение детализации низкоуровневого кода ] . Бит_31 управляет декрементом верхнего элемента в стеке возврата, когда тот используется в качестве счётчика циклов в блоковых операциях.
Одна микроинструкция исполняется за один такт. Каждая машинная инструкция вызывает выполнение двух и более микроинструкций.
5.3.4 Возможности архитектуры
Родовые черты WISC CPU/16 в архитектуре RTX 32P легко узнаваемы. Были реализованы самые очевидные пути её улучшения: добавление адресной логики и изоляция стека возвратов от системной шины данных на время вызова подпрограмм и возврата из них. Эти изменения вместе с уникальным форматом инструкций RTX 32P позволяют выполнять вызовы, возвраты и переходы «бесплатно» в том смысле, что они могут комбинироваться с другими операциями.
==106
==107
RTX 32P работает в два раза быстрее, чем скорость обращения к системной памяти, получая два такта на цикл памяти и минимум два такта на инструкцию.
Есть несколько способов использования формата инструкций RTX 32P, не все из которых очевидны поначалу. Одним из них является выполнение ветвлений программы. В RTX 32P нет прямой аппаратной поддержки условных переходов [* !!! ] , так как они сильно замедляют выполнение следующей инструкции или требуют чересчур быстрой программной памяти. Условные переходы выполняются с использованием специального кода операции «0BRANCH», совмещённого с вызовом подпрограммы для перехода на нужный адрес. Подготовка к вызову подпрограммы [* т.е. сохранение адреса инструкции, которая следует за вызовом подпрограммы, в стеке возврата ] отрабатывается аппаратурой одновременно с выяснением равенства верхнего элемента стека нулю ( в этом случае должен делаться переход ). Если переход нужен, из стека адресов возврата удаляется верхний элемент, превращая вызов подпрограммы в переход [* из стека удаляется только что положенный в него «адрес возврата» ] и выполнение продолжается. В противном случае имитируется немедленный выход из подпрограммы: верхний элемент стека возврата [* только что помещённый туда адрес ] используется для немедленного «возврата» управления, то есть перехода на инструкцию, расположенную после команды условного перехода. Цена такого решения: три такта в случае перехода и четыре такта в случае отказа от него. Напомним, что время обращения к памяти составляет два такта.
[* пояснения. Хотел чего-то умное здесь написать, но забыл что именно. Оставлю на всякий случай ].
Другой интересной возможностью RTX 32P является быстрый доступ к любому адресу памяти, как к переменной. Операция может использоваться притом даже, что 0-операндный формат требует ещё одного слова в памяти для адреса переменной. Хитрость в том, что специальный код операции комбинируется с вызовом функции, где адрес «функции» является на самом деле адресом нужной переменной. Затем микрокод перехватывает значение переменной, как только схема выборки инструкций её считает, и сразу же выполняет возврат из «функции», до того как «код» начнёт исполняться.
Основной смысл обсуждения этих двух приёмов - показать, что у аппаратуры есть возможности, неочевидные для программиста, использующего обычные компьютеры. Такие возможности особенно удобны при организации доступа к структурам данных ( например, дерево решений экспертной системы ) и на самом деле позволяют проводить прямые вычисления структур данных [* !!! ] . Подобное исполнение должно сопровождаться сохранением данных в специальном формате с 9-разрядным тегом ( соответствующим коду операции пользователя ) и 23-разрядным адресом вызова подпрограммы/перехода на следующий элемент структуры или команды возврата из подпрограммы для нулевого ( «nil» ) указателя.
Важной особенностью RTX 32P является возможность пошагового выполнения команд. При этом, используя операцию установки регистра микроинструкции, управляющий компьютер получает полный контроль над всеми ресурсами процессора. Процедура состоит из подготовки нужных регистров, загрузки самой микроинструкции, проведения одного цикла тактирования и считывания результата. Такая техника делает разработку микрокода достаточно очевидным делом, а дорогую внешнюю аппаратуру ненужной, сильно упрощает написание тестовых и диагностических программ.
==108
RTX 32P поддерживает обработку прерываний, включая исключения по переполнению и антипереполнению обоих стеков: как данных, так и возврата. Обычной реакцией на такие прерывания является откачка нужной половины проблемного буфера в системную память или наоборот подкачка оттуда. Такой механизм позволяет приложениям использовать стеки почти любой глубины. Практика показывает, что при длине буфера 512 элементов типичная программа на языке FORTH некогда не столкнётся с его переполнением.
5.3.5 Реализация и область применения
RTX 32P выполнен по 2.5µm КМОП технологии стандартных ячеек в виде набора из двух микросхем. Кристалл данных, включающий АЛУ, стек данных и отвечающие за работу АЛУ разряды памяти микрокода, упакован в 84-контактный безвыводной корпус LCC. Кристалл управления, включающий всё остальное, помещён в 145-контактный корпус PGA. Тактовая частота 8 MHz.
RTX 32P проектировался под управляющие приложения реального времени с упором на компактные и малопотребляющие встраиваемые системы. Как уже сообщалось, RTX 32P - прототип коммерческого процессора, который, в момент написания, планировалось назвать «RTX 4000». Этот новый процессор обладает рядом достоинств, делающих его пригодным для приложений реального времени и использования в качестве сопроцессора в персональных компьютерах. Список включает: упаковку в один кристалл, добавление в систему постоянной памяти, позволяющее самостоятельную работу, аппаратную поддержку вычислений с плавающей запятой, заметное увеличение тактовой частоты и встроенную поддержку микросхем динамической памяти. Некоторые версии могут быть лишены коких-либо из перечисленных свойств. Кроме того, архитектура будет подправлена в направлении улучшения поддержки языков Си, Ada и LISP. Для этого предполагается разрешить использование поля адреса инструкции для задания 21-разрядных констант. Это позволит быстрее проводить очень важные операции, подобные адресации по указателю кадра со смещением.
Данные для этого раздела основаны на описаниях WISC CPU/32 в Koopman ( 1987c ), и Koopman ( 1987d ) и обзору RTX 32P в Koopman ( 1989 ).
==108
